|
|
 |
| Авторизация |
|
|
|
| Поиск по указателям |
|
|
|
|
|
|
|
 |
|
|
|
| Sutton R.S., Barto A.G. — Reinforcement Learning |
|
|
|
| Предметный указатель |
N-step backups 164—166 191
N-step returns 165—166 191
N-step TD methods 164—168
N-step TD methods and Monte Carlo methods 164—166 170—171 172
N-step TD methods and TD(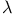 ) 169—172 191 ) 169—172 191
N-step TD methods, problems with 167
Naive Q() 184
Neural networks 21 22 23 225 263—266
Neuroscience 22 192
Non-Markov problems 63 64 153 190—191 258—259
Nonassociative problems and methods 20 25 45 284
Nonbootstrapping methods 220—222
Nonstationarity 30 38—39 128 195
Off-line updating 166
Off-policy methods 126—127 211
Off-policy methods, DP as 216
Off-policy methods, Monte Carlo 124—128
Off-policy methods, problems with bootstrapping in 216—220 222
Off-policy methods, Q-learning as 182
On-line updating 166 175 192
On-policy distribution 196 201 216—217
On-policy distribution vs. uniform distribution 247—249
On-policy methods 122 130
On-policy methods vs. off-policy methods 130 148—150
On-policy methods, Monte Carlo 122—124
On-policy methods, Sarsa as 145—148 179—181
One-step methods 164
One-step methods, backups diagrams for 243
Optimal control 16—17 83—84
Optimality and approximation 80—81
Optimality and value functions 75—80
Optimality of TD(0) 141—145
Optimistic initial values 39—41 215
Partially observable MDPs (POMDPs) 17 49 258—259
Pattern recognition 4 18
Peng's Q() 182 183—185(fig.) 192
Petroleum refinery: example 6—7
Planning 9 227—254 259—260
Planning and DP 229
Planning and heuristic search 250—252
Planning and learning 9 227—254
Planning and reinforcement learning 5 9
Planning and trajectory sampling 246—250
Planning by Q-learning 229—230
Planning in Dyna 230—238
Planning, deliberation vs. reaction in 9 231
Planning, incremental 230 253
Planning, integrated with action and learning 230—238
Planning, partial-order 228
Planning, state-space vs. plan-space 228
Pleasure and pain 7—8 57
Pole-balancing 59 64 83 202 221(fig.) see
Policy 52
Policy evaluation 90—93 94(fig.)
Policy evaluation by DP 90—93
Policy evaluation by Monte Carlo methods 112—117
Policy evaluation by TD methods 133—146
Policy evaluation for action values 116—117 145—146
Policy evaluation of one policy while following another 124—126
Policy evaluation, iterative 91—92
Policy evaluation, termination of 92
Policy improvement 93—98
Policy improvement and Monte Carlo methods 118—119
Policy improvement, theorem of 95—97
Policy iteration 97—100 see
Policy iteration by Monte Carlo methods 118—119
Policy, 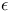 -greedy 122 -greedy 122
Policy, behavior 126
Policy, deterministic 92 291
Policy, equiprobable random 93
Policy, estimation 126
Policy, greedy 77 96 119
Policy, optimal 75
Policy, soft, -soft 100 122
Policy, stochastic 52
POMDPs see "Partially observable MDPs"
Prediction problem 90
Prior knowledge, using 14 56 260
Prioritized sweeping 239—240 241(fig.) 253 254
Prototype states 210
Psychology and reinforcement learning 16 48 254 see "Law "Secondary
Psychology and shaping 260
Psychology and stimulus traces 192
Psychology and stimulus-response associations 7
Pursuit methods 43—45
Q() 182—185 192
Q-functions 84 see
Q-learning 23 148—151 159 224 277
Q-learning and eligibility traces 182—185 192
Q-learning and planning 229—230
Q-learning, convergence of 148 159 192 216 218
Q-planning 229—230 231—232
Quasi-Newton methods 223
Queuing example, access-control 154—155 157
R-learning 153—155 160
Racetrack: example 127—128 131
Radial basis functions (RBFs) 208 224
Random walk: examples with n-step methods on 166—168
Random walk: examples, -return algorithm on 172
Random walk: examples, 19-state 167—168 172 178—179
Random walk: examples, batch updating on 142
Random walk: examples, five state 139—142 166—167
Random walk: examples, TD vs. MC methods on 139—142
Random walk: examples, TD() on 178—179
Random walk: examples, values learned by TD(0) on 140(fig.)
Random-sample one-step tabular Q-planning 229—230
RBFs see "Radial basis functions"
Reactive decision-making 231
Real-time DP 254
Real-time heuristic search 254
Recursive-least-square methods 223
Recycling robot: examples 6—7 55 56 66—68 78 83
Reference reward 41—42
REINFORCE algorithms 226
Reinforcement comparison methods 41—43 49 152
Reinforcement learning problem 4 51—85
Replacing traces or Replace-trace methods 186—189 221(fig.) see
Residual-gradient methods 224
RETURN 57—60 81 257
Return and value functions 68—69 75
Return, n-step, or corrected n-step truncated 165
Return, unified notation for 60—61
Rewards 7—8 51—52 53 54 81
| Rewards and goals 56—57
Rewards in the n-armed bandit problem 26
Rewards, reference 41
RMS error see "Root mean-squared error"
Robot examples 52 53 56 57 59 202 270
Robot examples, pick and place 54
Robot examples, recycling 55 56 66—68 78 83
Robot examples, trash collecting 6—7
Rod maneuvering: example 240—242
Root mean-squared error 141(fig.)
Rosenblatt, Frank 19
Rubik's cube: example 53
Sample backups 135 242 246 255
Sample models 129 227—228
Sample-average methods 28
Samuel, Arthur 21 22 109 225 see
Sarsa 145—148 159 210
Sarsa() 179—181 192
Sarsa() and TD() 179—180
Sarsa(), linear, gradient-descent 211—213 224
Search control 232
Secondary reinforcers 21
Selectional learning 18 19 20
Selective bootstrap adaptation 20 225—226
Self-play 14 266 268
Semi-Markov decision process 276—277 280—281
Sequential design of experiments 48 83
Shannon, Claude 21 84 267—268
Shortcut maze: example 236—238
Signature tables 225—270
Simulated experience 111
SNARCs (Stochastic Neural-Analog Reinforcement Calculators) 18
Soap bubble: example 116 131
Softmax method 30—31 49
Space shuttle payload processing (SSPP): case study 284—286
Sparse distributed memory 224
State aggregation 199—200 202 223 224 225 259
State nodes 68
State representations 61—62
State representations, augmenting 258—259
State representations, exploiting structure in 260
State values or State value functions 68—73 75—77 84
State(s) 52—55 61—65 81 83 see
State-action eligibility traces 179—180 188
STeLLA system 19
Step-size parameters 12—13 37 38—39
Stochastic approximation convergence conditions 39
Stochastic approximation methods 33
Supervised algorithm 33
Supervised learning 4 19 32 193 195
sweeps 91 246 see
Symmetries: in Tic-tac-toe 14—15
Synchronous algorithms 110
System identification 254 see
Tabular methods 80—81
Target or Target function 57 134 164—165 194—195
TD error 152 174—165 178 180
TD learning see "Temporal-difference learning"
TD() 22 169—175 191—192
TD() and Sarsa() 179—180
TD(), backward view of 173—175
TD(), convergence of 191—192 201
TD(), forward view of 169—173
TD(), function approximation and 198—200 201 223—224
TD(0) 23 134 135(figs.) 159
TD(0) and Sarsa 145
TD(0) and TD() 175
TD(0) vs. constant-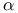 MC 139—142 MC 139—142
TD(0), -return algorithm and 171
TD(0), convergence of 138 159
TD(0), function approximation and 194 223
TD(0), optimality under batch updating of 141—145
TD(1) 175 188 216
TD-Gammon 14 261—267
TD-Gammon and heuristic search 251
TD-Gammon and Samuel's checker player 268
TDNN see "Time-delay neural network"
Temperature 31 42 49 278 285
Temporal-difference error see "TD error"
Temporal-difference learning (TD learning) 133—160 256
Temporal-difference learning (TD learning) and GPI 157—158
Temporal-difference learning (TD learning), actor-critic methods and 151—153
Temporal-difference learning (TD learning), advantages of 138—145
Temporal-difference learning (TD learning), bootstrapping and 138
Temporal-difference learning (TD learning), convergence of 138
Temporal-difference learning (TD learning), DP and 134 138
Temporal-difference learning (TD learning), eligibility traces and 163 190—191
Temporal-difference learning (TD learning), Monte Carlo methods and 133—145 175 188
Temporal-difference learning (TD learning), n-step 164—168
Temporal-difference learning (TD learning), off-policy control and 148—151
Temporal-difference learning (TD learning), on-policy control and 145—148
Temporal-difference learning (TD learning), one-step 148 158 159 164 179
Temporal-difference learning (TD learning), roots of 21—23 158—159
Temporal-difference learning (TD learning), Tic-tac-toe example 12—13
Terminal state 58
Testbed, 10-armed 28
Thorndike, Edward 17—18
Tic-tac-toe: example 10—15 see
Tile coding 204—208 215 224 272—273
Time steps 52
Time-delay neural network (TDNN) 287—289
Trace-decay parameter 173 189—190
Trajectory sampling 246—250 253 254
Transient DP 254
Transition graphs 67—68
Transition probabilities 66
trial-and-error learning 16 17—21
Tsitsiklis and Van Roy's counterexample 219—220
Undiscounted continuing tasks 61 153—155 160 224
Value functions 8—9 68—80 82 229 286
Value functions and DP 89—90
Value functions, function approximation and 193
Value functions, optimal 75—80
Value functions, policy evaluation and 90—93
Value functions, roots of 16 84
Value iteration 100—103
Value(s) 8 69 84
Value(s), in the n-armed bandit problem 26
Value(s), relative 154
Vision system: example 65
Watkins's Q() 182—184 192 211 213 224
Werbos, Paul 23 84 109 159 223
Widrow, Bernard 19 20 49 131 223 225
|
|
|
| Реклама |
|
|
|


 |
|
О проекте
|
|
О проекте