|
|
 |
| Авторизация |
|
|
|
| Поиск по указателям |
|
|
|
|
|
|
|
 |
|
|
|
| Cody R.P., Smith J.K. — Applied Statistics and the SAS Programming Language |
|
|
|
| Предметный указатель |
# (“pound” sign) 106—107 285
$ (dollar sign) 4
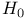 138—141 138—141
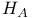 138—141 138—141
& (ampersand), format modifier 283
* (asterisk), comment indicator 15—18
*/ (asterisk slash), end of comment indicator 16—18
, (comma) data delimiter 281—282
- (dash), specifiying a like group of variables 62
-- (double dash), specifying a list of variables 62
. (period) 8
/ (slash) 14
/* (slash asterisk), begin comment indicator 16—18
: (colon), format modifier 282
; (semicolon) 4
? (question mark) 288—289
?, with INPUT 288—289
?? (double question mark) 288—289
??, with INPUT 288—289
@ (“at” sign) 144 199 287—288
@@ (double “at” sign) 153—154 287—288
Adding new observations see “SET” “PROC
Adjusted r-square 225
age calculation 103—105 356
Alpha, coefficient 276—277 393—394
alphanumeric 476
Alternative hypothesis 138—139 145—146 151
Ampersand (&), format modifier 283
Analysis of covariance see “Covariance”
Analysis of variance, assumptions for 151—159
Analysis of variance, contrasts 158—159 169—170
Analysis of variance, n-way factorial design 170—171
Analysis of variance, one-way 150—159
Analysis of variance, repeated measures designs see “Repeated measures ANOVA”
Analysis of variance, two-way 159—170
Analysis of variance, unbalanced designs 171—174
ANOVA procedure see “PROC ANOVA” “Analysis
APPEND procedure see “PROC APPEND”
Arrays 329—351
ASCII 300—302 304—305 338
Average, moving 391—392
Balanced designs 151
Bar graph 35—41
batch 2 18 300
Block chart 41
Boxplot 27—32
BY variables 32—34 43 110 166 322—326
CARDS statement 4 299—300 373
Character arrays 332—333
Character functions, COMPBL 367
Character functions, COMPRESS 368
Character functions, Concatenation (II) 168 371—372 377
Character functions, INDEX 373—374
Character functions, INDEXC 373—374
Character functions, INPUT 358—360
Character functions, LENGTH 366—367
Character functions, LOWCASE 375
Character functions, PUT 358—360
Character functions, REPEAT 365—367
Character functions, SCAN 373
Character functions, SOUNDEX 378
Character functions, SUBSTR 369—371
Character functions, TRANSLATE 375—376
Character functions, TRANWRD 376—377
Character functions, TRIM 371—372
Character functions, UPCASE 374—375
Character functions, VERIFY 368—369
Character informats 102
Character-to-numeric conversion 358—360
Chart procedure see “PROC CHART”
Chi-square 76—78
Chi-square from cell frequencies 79—80
CLASS statement, with PROC MEANS 33—34 45—53
CLASS, with ANOVA 154—155
coefficient alpha 276—277 393—394
Coefficient of variation 25 27 225
Colon (:), format modifier 282
Comma delimited data 281—282
Comment statement 15—18
Communality 256—262
COMPBL function 367
COMPRESS function 368
Concatenation operation 168 371—372 377
Confidence interval, about the mean 25—26
Confidence interval, about the odds ratio 83—86
Confidence interval, about the slope 126—128
CONTENTS procedure see “PROC CONTENTS”
CONTRAST statement 158—159 169—170
CORR procedure see “PROC CORR”
Correction for continuity 78
Correlation 115—137
Covariance, analysis of 174—178
Covariance, homogeneity of slope assumption 176—177
Cronbach’s coefficient alpha 276—277 393—394
Crossed designs 159—174
Crosstabulations 75—79
Cumulative frequencies 13 35
dash (-) 62
Data set 23—26 305—307 309—310
DATA step 13 23—24
Data vector see “Program Data Vector”
DATALINES 4 299—300 373
DATALINES4 4 299—300 373
DATASETS procedure see “PROC DATASETS”
date functions 356—358
date functions, DAY 358
Date functions, INTCK 358
Date functions, INTNX 358
date functions, MONTH 356—358
Date functions, WEEKDAY 357
date functions, YEAR 356—358
dates, working with 356—358
Day function 358
DDNAME 300—302
default options 26
Degrees of freedom, with ANOVA 155
Degrees of freedom, with Chi-square 78
Degrees of freedom, with regression 224—225
DELETE statement 293—360
Descending option, with PROC LOGISTIC 238
Descending option, with PROC SORT 426
Descriptive statistics 22—57
Designed regression 222—226
DIF function 360—361
DIM function 331—362
DISCRETE, option with PROC CHART 35—39
Display Manager 2
Distribution-free tests see “Nonparametric tests”
Division 8
DLM=, INFILE option 281—282
DO loop 163—164 183—184 214—215
Dollar sign ($) 4
Double dash (--) 62
DROP statement 311—312
DROP, data set option 311—312
DSD, INFILE option 281—282
Dummy variables 234—235
Duncan multiple range test 155—158
Efficiency techniques 311—317
Eigenvalues 256—258
else statement 7—9 72—73
END=, INFILE option 302—303
EOF=, INFILE option 302
Error in ANOVA 152
error messages 5
Error messages, suppressing 288—289
exponentiation 9
F ratio, with ANOVA 152—153
F1LEDEF 300—302
Factor analysis 250—264
| FACTOR procedure see “PROC FACTOR”
Factorial designs 170—174
FILE, statement 394
Filename 300—302
files, reading and writing 298—318
FIRST. 110—111
Fisher’s exact test 78
FMTSEARCH, system option 310
format library 309—310
Format list 286—287
FORMAT procedure see “PROC FORMAT”
FORMAT statement 67
FREQ procedure see “PROC FREQ”
Frequency bar chart 35—41
Frequency distributions 34—35
Functions see “Character functions” “Date “Numeric “Trigonometric
GLM procedure see “PROC GLM”
GOTO statement 393
Grand mean 151
Greenhouse — Geisser-Epsilon 188
GROUP=, option with PROC CHART 39—41
GROUP=, option with PROC RANK 142
HBAR 36—40
HIGH, with PROC FORMAT 73
Homogeneity or variance assumption 151
Hosmer and Lemeshow goodness-of-fit 238
Hotelling — Lawley trace 191—193
Huynh — Feldt Epsilon 188
ID statement, with PROC MEANS 47—48
ID statement, with PROC PRINT 11—12
ID statement, with PROC UNIVARIATE 31
If statement 9
Implicitly subscripted arrays 339—340
IN statement 420
IN=, option with merge 322—324
INDEX function 373—374
INDEXC function 373—374
INFILE options 281—282 302—304
INFILE statement 300—302
INFORMAT 282—285
Input function 358—360
Input statement 3^4
INPUT, column form 383—384
INPUT, list 280—282
INT function 354
INTCK function 358
Interaction 162
intercept 123
Interquartile range 27 32
Interrater reliability 82 277—279
INTNX function 358
Invalid data, checking for 368—369
Invalid data, overriding LOG messages 288—289
Item analysis 273—276
JCL 301—302
JOB statement 301
justification 4
Kappa, coefficient 82 277—279
KEEP statement 95
KEEP, data set option 403
Kuder — Richardson 276—277 393
L95 126—128
L95M 126—128
LABEL statement 63—65
Labels for SAS statements 393
LAG function 391—392 360—361
Large data sets, working with 311—317
LAST. 109—111
Least significant difference 156
Least squares 122
left justified 4
length function 366
LENGTH statement 366
LEVELS= 37—38
libname 306—307
Likert scale 66—70
Linear regression 121—124
LINESIZE (LS), system option 271
List-directed input 280—281
Lists of variables 62
Log transformation 353—354
logical operators 9
LOGISTIC procedure see “PROC LOGISTIC”
Logistic regression 235—247
Longitudinal data 101—114
LOW, with PROC FORMAT 73
LOWCASE function 375
LRECL, INFILE option 304
LSD 156
Macro variable 269 386—387
Mann — Whitney U-test 143
Mantel — Haenszel Chi-square for stratified tables 90—92
MAXDEC=n 6 24—25
McNemar’s test 81—83
MDY function 356
Mean function 354—355
Means procedure see “PROC MEANS”
Median 27 54
MERGE statement 321—324
Meta analysis see “Mantel — Haenszel...”
MIDPOINTS=, option with PROC CHART 37—38
Missing value 8
Missing values, changing 999 to missing 329—332
Missing values, changing N/A to missing 332—333
MISSOVER, option with INFILE 303
Moments 30—31
Month format 356—358
Month function 356—358
Month/day/year 356—358
Morse code, conversion to 338—339
multidimensional arrays 347—348
Multilevel sort 10—11
Multiple comparisons 155—158
Multiple lines per subject 106—109 285—286
Multiple regression 221—249
Multiplication 8
N function 355
Named input 433
Nested DO loops 214—215
Nesting in ANOVA 194
NMISS function 355
Nonexperimental regression 226—228
Nonparametric tests, two-sample, paired (Wilcoxon signed rank test) 28 31
Nonparametric tests, two-sample, unparied (Wilcoxon ranksum test) 143—145
NOPRINT option, with PROC CORR 274
NOPRINT option, with PROC FREQ 387
NOPRINT option, with PROC MEANS 46—47
NOPRINT option, with PROC REG 134
Normal probability plot 32
NOUNI 187
NPAR1WAY procedure see “PROC NPAR1WAY”
Null hypothesis 138—141
Numeric functions, INT 354
Numeric functions, LOG 353—354
Numeric functions, LOG10 354
Numeric functions, MAX 355
Numeric functions, MEAN 354—355
Numeric functions, MIN 355
Numeric functions, N 355
Numeric functions, NMISS 355
numeric functions, round 354
Numeric functions, SQRT 354
NWAY, option with PROC MEANS 46—48
Oblique rotations 258—259
OBS=, system option 316
Observation 3
Observation counter 266—267 337 369 383 391
Odds ratio 83—86
One-tailed test 138 145—146
one-way analysis of variance see “Analysis of variance”
|
|
|
| Реклама |
|
|
|


 |
|
О проекте
|
|
О проекте