|
|
 |
| Авторизация |
|
|
|
| Поиск по указателям |
|
|
|
|
|
|
|
 |
|
|
|
| Agresti A. — An introduction to categorical data analysis |
|
|
|
| Предметный указатель |
Logistic regression, multiple 122—129
Logistic regression, probability estimates 106—107 110—111 208 211 275
Logistic regression, quadratic term 108 136
Logistic regression, qualitative predictors 118—129
Logistic regression, residuals 115—118 274
Logistic regression, sample size and power 269—273
Logistic-normal model 231
logit 73 77—78 261
Logit models: adjacent-categories 216—218
Logit models: as generalized linear model 73
Logit models: baseline-category 206—211
Logit models: continuation-ratio 218—220
Logit models: cumulative 211—216
Logit models: linear trend 77—78 104 125 212 216
Logit models: loglinear models, equivalence 162—165 211
Logit models: matched pairs 229—233
Logit models: qualitative predictors 118—125
Loglinear models 73 80—93 145—167 174—199
Loglinear models as GLM with Poisson data 73 80 145—147
Loglinear models, (XY, XZ, YZ) 151 156 163 176—177 185
Loglinear models, (XZ, YZ) 151 154 156 176—177 185 195
Loglinear models, association graphs 175—180
Loglinear models, comparing models 156 185 194 196—198
Loglinear models, computer software 270 273—274
Loglinear models, degrees of freedom 154 196
Loglinear models, four-way tables 158—162
Loglinear models, goodness of fit 154—157 196
Loglinear models, homogeneous association 151 158 163 185
Loglinear models, independence 145—148
Loglinear models, inference 154—158 185—188 195—199
Loglinear models, logit models, equivalence 147 162—165 211
Loglinear models, model selection 165—167 178—180
Loglinear models, no three-factor interaction 151. See also Homogeneous association
Loglinear models, odds ratios 107—108 149 152 157 160
Loglinear models, residuals 91 155—156 181 242—243 268
Loglinear models, saturated 148—149
Loglinear models, three-way tables 150—158 176—177 185—188
LogXact 133 194 203 264 272
Lung cancer and chemotherapies 222—223
Lung cancer and smoking 45—46 47 60—63 68 139 168
Lung cancer meta analysis 60—62
Lymphocytic infiltration 203—204
Mammography 49 221
Mann — Whitney test 38
Mantel — Haenszel estimator 62 122 231 251
Mantel — Haenszel test See Cochran — Mantel — Haenszel test
Marginal association 57—59 153 176—180
Marginal distribution 17 57—58
Marginal homogeneity 227 234 239—242
Marginal maximum likelihood 231
Marginal table 54 57
Marginal table, same association as partial table 176—180
Marijuana, cigarette, and alcohol use 152—157 172 178—180
Matched pairs 226—249
Matched pairs, CMH approach 229—231
Matched pairs, dependent proportions 227—229
Matched pairs, logit model 230—233
Matched pairs, McNemar test 227—228
Matched pairs, odds ratio estimate 231—233 251
Matched pairs, ordinal data 237—242
Matched pairs, Rasch model 233
Maximum likelihood 8—10
McNemar test 227—228 229—230 231 249
Measures of association: difference in proportions 20 227—229
Measures of association: kappa 246
Measures of association: odds ratio 22
Measures of association: relative risk 21—22
Mental impairment, life events, and SES 221—222
Meta analysis 62
Meta analysis of lung cancer 60—62
Mice and developmental toxicity 219—220
Mid P-value 43—44 50
Midranks 37 188 189
Migraine headaches 68
Missing people 138—139
Mixed model 231
ML See Maximum likelihood
Mobility, residential 252
Model matrix 198
Model selection 126—129 165—167 178—180
Motorway accidents, Ml 4—8
Multicollinearity 126
Multinomial distribution 8 205
Multinomial logit model 206
Multinomial sampling 8 19 205
Multiple correlation 129
Multiple sclerosis diagnoses 254
Murder rates 47 67
Mutual independence 151
Myocardial infarction and aspirin 20—25 45
Myocardial infarction and coffee 140
Myocardial infarction and diabetes 232—233
Myocardial infarction and smoking 25—27 136—137
Natural parameter 73
NCAA athlete graduation rates 138
Nested models 196
Newton — Raphson algorithm 93—94 195—196
No three-factor interaction 151.See also Homogeneous association
Nominal response variables 2—3 188—190 205—211 234—237 239—240 242—246
Normal distribution 73—74 97
Observational study 27
Odds 22 107
Odds ratio 22 258
Odds ratio and logistic regression models 107—108
Odds ratio and loglinear models 149 152 157 160
Odds ratio and relative risk 25—27 142
Odds ratio and zero counts 25 191—192
Odds ratio with case-control data 25—27 108 232—233
Odds ratio with retrospective data 25—27 232—233
Odds ratio, ASE 24
Odds ratio, bias 25 191
Odds ratio, conditional 57 59 61—64 152 176
Odds ratio, confidence intervals 24 44 66 157 269
Odds ratio, exact inference 44 64—66 269
Odds ratio, homogeneity, in 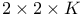 tables 63—64 66 122 269 tables 63—64 66 122 269
Odds ratio, invariance properties 23
Odds ratio, local 183
Odds ratio, Mantel — Haenszel estimate 62 122 231
Odds ratio, matched pairs 231
Offset 86 271
Ordinal data 2—3
Ordinal data in logit models 211—220
Ordinal data in loglinear models 182—185 187—188
Ordinal data, exact tests 45 268
Ordinal data, marginal homogeneity 240—242
Ordinal data, ordinal versus nominal treatment of data 36—37 49
Ordinal data, quasi symmetry 237—241
Ordinal data, scores, choice of 37—38 184
Ordinal data, testing independence 34—39 184—185 187—188
Ordinal data, trend in proportions 34—39
Ordinal quasi symmetry 237—241 277—278
Osteosarcoma 203—204
Overdispersion 5 219—220
P-value and Type I error probability 41—43
Paired comparisons 246—249
Parameter constraints 120—121 148—149
Partial association 54 57
Partial association, partial table 54
Partial association, same as marginal association 176—180
Partitioning chi-squared 32—33 52 198 261
Passive smoking and lung cancer 68
Pathologist diagnoses 242—246
Pearson chi-squared statistic 28 89
Pearson chi-squared statistic and residuals 51 91 115 155 196
Pearson chi-squared statistic, chi-squared distribution 28 196
Pearson chi-squared statistic, comparing models 197—198
Pearson chi-squared statistic, degrees of freedom 28 111 154 196
Pearson chi-squared statistic, exact test 42—45
Pearson chi-squared statistic, goodness of fit 89 113 154 196
Pearson chi-squared statistic, independence 30 52
| Pearson chi-squared statistic, loglinear model 154 196
Pearson chi-squared statistic, sample size for chi-squared approximation 34 194
Pearson chi-squared statistic, sample size, influence on statistic 34 52
Pearson chi-squared statistic, two-by-two tables 52
Pearson residual 51 91
Pearson residual, Binomial GLM 115 274
Pearson residual, independence 51
Pearson residual, Poisson GLM 91 156 196 271
Pearson, Karl 257—260
Poisson distribution 4
Poisson distribution, binomial, connection with 99
Poisson distribution, mean and standard deviation 5
Poisson distribution, overdispersion 5
Poisson distribution, Poisson loglinear model 80—93 145—167 198
Poisson distribution, Poisson regression 80—93
Poisson distribution, Poisson sampling 5—6 18
Poisson distribution, residuals 91 155—156
Poisson regression 80—93
Poisson regression, computer software 270
Poisson regression, degrees of freedom 89
Poisson regression, goodness of fit 89—93
Poisson regression, identity link 85 101 102
Poisson regression, interaction 102
Poisson regression, loglinear model 80—84 145—167 198
Poisson regression, rate data 86—87 99
Political ideology and party affiliation 201—203 213—215 217
Political party and gender 30—33
Political party and race 48
Political views, religious attendance, sex, and birth control 170—171
Polychotomous models 205—211
Popularity of prime minister 226—229
Power 130—132
Practical vs. statistical significance 52 161—162
Premarital sex and birth control 181
Premarital sex and extramarital sex 238—239 241—242
Presidential voting and racial items 169
Prime minister's performance 226—229
Probability estimates 106—107 110—111 208 211 275
Probit model 79—80 144 270 272
Profile likelihood 272
Promotion discrimination 65—66 69 70
Proportional odds model 212—216 241—242 264 276
Proportions: as sample mean 10
Proportions: Bayesian estimate 13
Proportions: dependent 227—229
Proportions: difference of 20 227—229
Proportions: estimating using models 106—107 110—111 208 211 275
Proportions: independent 20
Proportions: inference 10—12 15
Proportions: ratio of (relative risk) 21—22
Proportions: standard error 10
Psychiatric diagnosis and drugs 48
Psyllium and cholesterol 224 254
Quasi independence 243—244 277
Quasi symmetry 235—241 244—245 248 253 256 262 277—278
Racial opinion items 169
Radiation therapy and cancer 50
Random component (GLM) 72
Random effect 231
Ranks 37 38 188 189
Rasch model 233 241 261
Rater agreement 242—246
Rates 86—87 99 100 101
Reincarnation, belief in 14
Relative risk 21—22
Relative risk and odds ratio 25—27 142
Relative risk, confidence interval 47
Religious attendance 170—171 200—201
Religious mobility 251—252
Residential mobility 252
Residuals: adjusted 31 91 118 155—156 271
Residuals: binomial GLM 115—118
Residuals: deviance 96
Residuals: independence 31 181 242—243 268
Residuals: Pearson 51 91 115 156 196 271
Residuals: PoissonGLM 91 155—156
Residuals: standardized 91
Response variable 2 166
Retrospective study 26 231—233
Ridits 275
Russian roulette (Graham Greene) 13
Sample size determination 130—132
Sampling 3—8 18—19
Sampling zero 191
SAS: CATMOD 274—276
SAS: CMH methods 190 268—269 274—275
SAS: FREQ 190 267—269
SAS: GENMOD 269—274 277—278
SAS: LOGISTIC 270—273
SAS: logistic regression 270—273
SAS: loglinear models 273—274
SAS: Poisson regression 270—271
SAS: two-way tables 267—269
Saturated model: generalized linear model 96
Saturated model: logistic regression 114
Saturated model: loglinear models 148—149
Score test 89 94—95
Scores, choice of 37—38 184
Seat belt and death 169—170
Seat belt and injury 47 158—162 225
Sensitivity 51
Sex opinions 252
Sexual intercourse and gender and race 138
Significance, statistical versus practical 52 161—162
Silicon wafer defects 98—99
Simpson's paradox 57 67 258
Small samples: 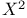 and and 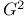 34 194 34 194
Small samples: adding constants to cells 25 191—192
Small samples: exact inference 39—45 64—66 132—135
Small samples: infinite parameter estimates 133—135 191—193 203—204
Small samples: zero counts 134 190—192
Smoking and lung cancer 45—46 47 60—63 139 168
Smoking and myocardial infarction 25—27 136—137
Snoring and heart disease 75—80
Soccer attendance and arrests 100—101
Soccer odds 46
Space shuttle and O-ring failure 135
Sparse tables 190—194
Spearman's rho 38
Specificity 51
SPSS 267 268 271 274 276 278
Square tables 226—249
Standardized regression coefficient 142
Standardized residuals see Pearson residuals
StatXact 44 65 194 264 268 269
Stepwise model-building 127—129 179—180 273
Strokes and aspirin 45
Structural zero 191
Subject-specific effect 231 241
Sufficient statistics 195 204
Symmetry 227 234—235 239—241 253 277—278
Systematic component (GLM) 72
Tea tasting 40—44
Teen sex and premarital sex 181 252
Teenage birth control and religious attendance 200—201
Tennis rankings 246—248 255
Tetrachoric correlation 258
Three-factor interaction 151 160—162 164
Three-way tables 53—66 150—158 176—177 185—190
Tolerance distribution 79
Trains and collisions 101
Trend test 34—39 143 188 268
Uniform association model 183
Wald statistic 88 109
Weighted least squares 261 264 276
Wilcoxon test 38
Women tennis players 246—248
Yates continuity correction 43
Yule's Q 258
Yule, G.Udny 258—259
|
|
|
| Реклама |
|
|
|


 |
|
О проекте
|
|
О проекте