|
|
 |
| Авторизация |
|
|
|
| Поиск по указателям |
|
|
|
|
|
|
|
 |
|
|
|
| Cappe O., Ryden T., Moulines E. — Inference in Hidden Markov Models |
|
|
|
| Предметный указатель |
Absorbing state 12
Accept-reject algorithm 166—169 173
Accept-reject algorithm in sequential Monte Carlo 224 261
Acceptance probability in accept-reject 169
Acceptance probability in Metropolis-Hastings 171
Acceptance ratio in Metropolis-Hastings 171
Acceptance ratio in reversible jump MCMC 486
Accessible set 517
AEP see “Asymptotic equipartition property”
Asymptotic equipartition property 568 see
Asymptotically tight see “Bounded in probability”
atom 518
Auxiliary variable 260
Auxiliary variable in sequential Monte Carlo 256—264
Averaging in MCEM 403 424
Averaging in SAEM 411
Averaging in stochastic approximation 409 429
Backward smoothing, decomposition 70
Backward smoothing, kernels 70—71 125 130
Bahadur efficiency 559
Balance equations, detailed 41
Balance equations, global 41
Balance equations, local 41
Baum — Welch see “Forward-backward”
Bayes, formula 71
Bayes, operator 102
Bayes, rule 64 157
Bayes, theorem 172
Bayesian information criterion 560 563 568
Bayesian, decision procedure 466
Bayesian, estimation 358 465
Bayesian, model 71 466
Bayesian, network see “Graphical model”
Bayesian, posterior see “Posterior”
Bayesian, prior see “Prior”
BCJR algorithm 74
Bearings-only tracking 23—24
Bennett inequality 584
Bernoulli — Gaussian model 196
BIC see “Bayesian information criterion”
Binary deconvolution model 373
Binary deconvolution model, estimation using EM 374
Binary deconvolution model, estimation using quasi-Newton 374
Binary deconvolution model, estimation using SAME 500
Binary symmetric channel 7 8
Bootstrap filter 238 254—256 259
Bounded in probability 334
Bryson — Frazier see “Smoothing”
Burn-in 395 491
Canonical space 38
Capture-recapture model 12 479
Cauchy sequence 600
CGLSSM see “State-space model”
Chapman — Kolmogorov equations 36
Coding probability 565 568
Coding probability, mixture 567
Coding probability, normalized maximum likelihood 566
Coding probability, universal 566
Communicating states 507
Companion matrix 16 30
Computable bounds 185
Conditional likelihood function 218
Conditional likelihood function, log-concave 225
Contrast function 436
Coordinate process 38
Coupling inequality 536
Coupling of Markov chains 536—539
Coupling set 537
Critical region 564
Darroch model 12
Data augmentation 476
Dirichlet distribution 470 567
Disturbance noise 127
Dobrushin coefficient 96
Doeblin condition 97
Doeblin condition for hidden Markov model 555
Drift conditions for hidden Markov model 555
Drift conditions for Markov chain 531—534 542—545
Drift conditions, Foster — Lyapunov 542
ECM see “Expectation-maximization”
Effective sample size 235
Efficiency 574
Efficiency, Bahadur 575
Efficiency, Pitman 574
Efficient score test 461
EKF see “Kalman extended
em see “Expectation-maximization”
Equivalent parameters 445
Error, exponent 575
Error, overestimation 562
Error, underestimation 562
Exchangeable distribution 472
Expectation-Maximization 347—351
Expectation-maximization, convergence of 387—392
Expectation-maximization, ECM 391
Expectation-maximization, for MAP estimation 358
Expectation-maximization, for missing data models 357
Expectation-maximization, in exponential family 350
Expectation-maximization, intermediate quantity of 347
Expectation-maximization, SAGE 392
Exponential family 350
Exponential family natural parameterization 467
Exponential family natural parameterization of the Normal 149
Exponential forgetting see “Forgetting”
Filtered space 37
Filtering 54
Filtration 37
Filtration natural 38
Fisher identity 352 360 452
Forgetting 100—120
Forgetting exponential, of time-reversed chain 455
Forgetting, exponential 109 440
Forgetting, strong mixing condition 105 108
Forgetting, uniform 100 105—110
Forward smoothing, decomposition 66
Forward smoothing, kernels 66 101 327
Forward-backward 56—66
Forward-backward, 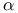 see “Forward variable” see “Forward variable”
Forward-backward, 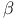 see “Backward variable” see “Backward variable”
Forward-backward, backward variable 57
Forward-backward, Baum — Welch denomination 74
Forward-backward, decomposition 57
Forward-backward, forward variable 57
Forward-backward, in finite state space HMM 123—124
Forward-backward, in state-space model 154
Forward-backward, scaling 61 74
Gaussian linear model 128 149
Generalized likelihood ratio test see “Likelihood ratio test”
Gibbs sampler 180—182
Gibbs sampler in CGLSSM 194
Gibbs sampler in hidden Markov model 475—480
Gibbs sampler, random scan 181
Gibbs sampler, sweep of 180 397 478
Gibbs sampler, systematic scan 181
Gilbert — Elliott channel 6
Global sampling see “Resampling global”
Global updating see “Updating of hidden chain”
Gram — Schmidt orthogonalization 135
Graphical model 1 4
Growth model, comparison of SIS kernels 230—231
Growth model, performance of bootstrap filter 240—242
Hahn — Jordan decomposition 91
Harris recurrent chain see “Markov chain” “Harris
Harris recurrent set 526
Hidden Markov model 1—5 42—44
Hidden Markov model, aperiodic 553
Hidden Markov model, discrete 43
Hidden Markov model, ergodic 33
Hidden Markov model, finite 6—12
Hidden Markov model, fully dominated 43
| Hidden Markov model, hierarchical 46—47
Hidden Markov model, in biology 10
Hidden Markov model, in ion channel modelling 13
Hidden Markov model, in speech recognition 13
Hidden Markov model, left-to-right 33
Hidden Markov model, likelihood 53
Hidden Markov model, log-likelihood 53
Hidden Markov model, normal see “Normal hidden Markov Hidden Markov model model”
Hidden Markov model, partially dominated 43
Hidden Markov model, phi-irreducible 553
Hidden Markov model, positive 553
Hidden Markov model, recurrent 553
Hidden Markov model, transient 553
Hidden Markov model, with finite state space 121—126
Hilbert space 612
Hitting time 507 515
HMM see “Hidden Markov model”
Hoeffding inequality 292
Homogeneous see “Markov chain”
HPD (highest posterior density) region 240
Hybrid MCMC algorithms 179
Hyperparameter see “Prior”
Hypothesis testing, composite 559 561 563 575
Hypothesis testing, simple 564
Ideal codeword length 565
Identifiability 444—451 462 472 559 562
Identifiability in Gaussian linear state-space model 382
Identifiability of finite mixtures 448
Identifiability of mixtures 448—449
Implicit conditioning convention 58
Importance kernel see “Instrumental kernel”
Importance sampling 173 210—211 287—295
Importance sampling, self-normalized 211 293—295
Importance sampling, self-normalized, asympotic normality 293
Importance sampling, self-normalized, consistency 293
Importance sampling, self-normalized, deviation bound 294
Importance sampling, sequential see “Sequential Monte Carlo”
Importance sampling, unnormalized 210 287—292
Importance sampling, unnormalized, asymptotic normality 288
Importance sampling, unnormalized, consistency 288
Importance sampling, unnormalized, deviation bound 292
Importance weights 173
Importance weights, normalized 211
Importance weights, normalized, coefficient of variation of 235
Importance weights, normalized, Shannon entropy of 235
Incremental weight 216
Information divergence rate 568
Information matrix 458
Information matrix, observed 436
Information matrix, observed, convergence of 459
Information parameterization 148—149
Initial distribution 38
Innovation sequence 136
Instrumental distribution 210
Instrumental kernel 215
Instrumental kernel, choice of 218
Instrumental kernel, optimal 220—224
Instrumental kernel, optimal, local approximation of 225—231
Instrumental kernel, prior kernel 218
Integrated autocorrelation time 191
Invariant measure 511 527
Invariant measure sub-invariant measure 527
Inversion method 242
Irreducibility measure, maximal 516
Irreducibility measure, of hidden Markov model 550
Irreducibility measure, of Markov chain 515
Jacobian 480 486 489—490
Kalman, extended filter 228
Kalman, filter 141—142
Kalman, filter, gain 141
Kalman, filtering with non-zero means 142
Kalman, predictor 137—139
Kalman, predictor, gain 138
Kalman, unscented filter 228
Kernel see “Transition”
Kraft — McMillan inequality 565
Krichevsky — Trofimov mixture 567
Kullback — Leibler divergence 348
Label switching 473
Lagrange multiplier test 461
Large deviations 578
Latent variable model 2
Law of iterated logarithm 565
Level 564
Level, asymptotic 564
Likelihood 53 357 437—439
Likelihood in state-space model 139
Likelihood ratio test 460—462
Likelihood ratio test, generalized 461 559 564 568 578
Likelihood, conditional 65 66 438
Linear prediction 131—136
Local asymptotic normality 437
Local updating see “Updating of hidden chain”
Log-likelihood see “Likelihood”
Log-normal distribution 480
Louis identity 352
Lyapunov function 417
Lyapunov function, differential 426
MAP see “Maximum a posteriori”
Marcinkiewicz — Zygmund inequality 292
Markov chain Monte Carlo 169—186
Markov chain, aperiodic 514 535
Markov chain, canonical version 39
Markov chain, central limit theorem 548 549
Markov chain, ergodic theorem 514 536
Markov chain, geometrically ergodic 542
Markov chain, Harris recurrent 526
Markov chain, homogeneous 2
Markov chain, irreducible 508
Markov chain, law of large numbers 546
Markov chain, non-homogeneous 40 163
Markov chain, null 513 528
Markov chain, on countable space 507—514
Markov chain, on general space 514—549
Markov chain, phi-irreducible 515
Markov chain, positive 528
Markov chain, positive recurrent 513
Markov chain, recurrent 511
Markov chain, reverse 40
Markov chain, reversible 41
Markov chain, solidarity property 510
Markov chain, strongly aperiodic 535
Markov chain, transient 511
Markov jump system see “Markov — switching model”
Markov property 39
Markov property, strong 40
Markov-switching model 4
Markov-switching model, maximum likelihood estimation 463
Markov-switching model, smoothing 86
Matrix inversion lemma 149 152
Maximum a posteriori 358 467 495—504
Maximum a posteriori, state estimation 125 208
Maximum likelihood estimator 358 435
Maximum likelihood estimator, asymptotic Maximum likelihood estimator, normality 437 459
Maximum likelihood estimator, asymptotics 436—437
Maximum likelihood estimator, consistency 436 440—444 459
Maximum likelihood estimator, convergence in quotient topology 444
Maximum likelihood estimator, efficiency 437
Maximum marginal posterior estimator 466
Maximum marginal posterior estimator in CGLSSM 208
MCEM see “Monte Carlo EM”
MCMC see “Markov chain Monte Carlo”
MDL see “Minimum description length”
Mean field in stochastic approximation 426
Mean square, convergence 612
Mean square, error 614
Mean square, prediction 614
Measurable function 599
Measurable set 599
Measurable space 599
|
|
|
| Реклама |
|
|
|


 |
|
О проекте
|
|
О проекте