|
|
 |
| Авторизация |
|
|
|
| Поиск по указателям |
|
|
|
|
|
|
|
 |
|
|
|
| Lander E.S., Waterman M.S. (eds.) — Calculating the Secrets of Life: Applications of the Mathematical Sciences to Molecular Biology |
|
|
|
| Предметный указатель |
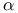 -Helix 242—248 254 -Helix 242—248 254
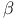 -sheet 242—248 254 -sheet 242—248 254
4-plat knots 215—216 220 222
Adenine (A) 8 9 99
Algorithms 35—36 84—86 87
Algorithms, approximate pattern matching 78—79
Algorithms, difference measures 72—73
Algorithms, dynamic programming 60—64 78 82 84 85 86 109
Algorithms, gap cost penalties 70—72
Algorithms, global alignment 58—64 94—99
Algorithms, heuristic 82—84
Algorithms, in evolutionary analysis 106 110—112
Algorithms, in genetic mapping 35—36
Algorithms, in physical mapping 46—51
Algorithms, K-best alignments 76—78
Algorithms, local alignment 65—70 99—106
Algorithms, multiple alignments 73—76
Alleles 6
Amino acids 4 57 “Protein “Sequence
Amplification see “Polymerase chain reaction”
Ancestry see “Evolutionary analysis”
ANREP systems 87
Antidiagonals 62 79—80
APC gene 34 37—38
Approximate pattern matching 78—79 86
Approximate repeats 87
ARIADNE systems 87
Assay techniques 2—3
Autosomes 26
Base pairs 8 26 48 153 154 163 179 185 188 189 191 194 204 249 “Thymine” “Cystosine” “Guanine” “Uracil”)
Bayesian statistics 35
Bernoulli random variables 102 125
Biochemistry 2—5
Biosequences see “Databases of DNA sequences” “Sequence “Sequencing
BLASTA algorithm 82—84
Booth — Leuker algorithm 50—51
BRCAl (breast cancer) gene 33
Cancer 33 34 37—42 58 91 183 196
Catenanes 205 212
Cauchy’s formula 136
Cellular structures 9
Chaperonins 238—239
Chen — Stein method 102 106 110
Chimeras 51
Chirality 213—215
Chromosomal walking 17 18 42 43
Clones and cloning 13 14 26 42—43 209
Closed circular DNA 153—154 155 156 157 181 204
Coalescent 117 119—121
Coalescent, combinatorial structures 119 136—148
Coalescent, Ewens sampling formula 119 122—124 136—139
Coalescent, K-allele model 130—132
Coalescent, likelihood methods 146—148
Coalescent, tree construction and movement 124—127 (see also “Finitely-many-sites model” “Infinitely-manysites
Codons 12 115 239
Colon cancer 34 37—42
Combinatorics 119 136—148 185
Computing time and memory capacity, algorithmic efficiencies 35—36 84—86 87
Computing time and memory capacity, approximate pattern matching 79 87
Computing time and memory capacity, dynamic programming, algorithms 62—63 64 68 83 84
Computing time and memory capacity, gap cost functions 72
Computing time and memory capacity, heuristic algorithms 83—84
Computing time and memory capacity, K-best paths 77
Computing time and memory capacity, multiple alignments 75
Computing time and memory capacity, parallel processing 79—81 84
Computing time and memory capacity, sublinear similarity searches 84—85
Consecutive ones property 50
Consensus scores 76
Contigs 47—50
Crick and Watson model 153 204—205
Crossovers 27—29
Cruciforms 154
Crystallography 202 203 240
Cystic fibrosis (CF) 16—18 20—21 26
Cytosine (C) 8 9 99
Databases of DNA sequences 13 17 56 81 87
Databases of DNA sequences, similarity searches in 78—79 82—86 87 91—92 94 BLASTA”)
Dayhoff matrix 66 67 83
Diagnostics see “Genetic diagnostics”
Difference measures 72—73
Diffusion processes 37—42 148
Dimers 212
DNA (deoxyribonucleic acid) 8—9 92
DNA (deoxyribonucleic acid), primers 13 15 16
DNA (deoxyribonucleic acid), protein binding 166—167 168 170—171 181
DNA (deoxyribonucleic acid), transcription 9—12 154 179 196—198 204—205 “Protein “Sequence “Sequencing “Strand “Supercoiling”)
DNA polymerases 8 16 154
DNA polymorphisms and mutations 8—9 16—17 26 30 34 57 106
DNA polymorphisms and mutations, as markers 31 34
DNA polymorphisms and mutations, in evolutionary analysis 114—135
DNA polymorphisms and mutations, in mitochondria 115—116 117 118 148—149
DNA polymorphisms and mutations, minimal cost alignments 72—73
DNA polymorphisms and mutations, rates of 66 67 116 117 124—125
Dot plots 68 70
Duplex unwinding elements (DUEs) 183 194 195
Dynamic programming algorithm 60—64 78 82 84 85 86 109 251
Edit graphs 59—61 68—70 75
Effective population size 117
Efficient algorithms 35—36 84—86 87
Electron microscopy 202 211 227
Electrostatic interactions 251
Energetics 154 180 182 186—195
Enzymes 3 7 180 238
Eve hypothesis 116
Evolutionary analysis 57—58 90—94
Evolutionary analysis, coalescent structures 117 119—135 148—149
Evolutionary analysis, common origins 57 248
Evolutionary analysis, extremal statistical methods 106—112
Evolutionary analysis, minimal cost alignments 72—73
Evolutionary analysis, multiple alignments 73 76
Evolutionary analysis, random combinatorial structures 136—148
Evolutionary analysis, trees 73 76 87 124 129 132 266
Evolutionary analysis, use of mitochondrial DNA 57—58 90—94 115—116 117 148—149
Ewens sampling formula (ESF) 119 122—124 136—139
Extremal statistical methods 106—112
Extremal statistical methods, global sequence comparisons 94—99
Extremal statistical methods, local sequence comparisons 99—106
False negatives and positives 51
Familial adenomatous polyopsis (FAP) 37—38
FASTA algorithm 82 83 84
Fingerprinting methods 42—47
Finitely-many-sites model 132—135
Fleming — Viot process 148
Foldases 237—238
Fourier transforms, coefficient 240
Fractionation 2—3
Free energy 154 180 182 186—195
Gap costs 70—72 77—78
Gaussian processes 41
Gel electrophoresis 210—211 227
GENBANK database 81
Gene splicing see “Recombinant DNA technology”
Gene therapy 18
Generalized Levenshtein measure 73 87
genetic code 12 239
Genetic diagnostics 16 17
Genetic distance 28—29
Genetic heterogeneity 34
Genetic maps and mapping 16 18—19 26 27—30 51
Genetic maps and mapping, and incomplete pedigree information 30 31 34—35
Genetic maps and mapping, and maximum likelihood estimation 34—42
Genetic maps and mapping, and non-Mendelian genetics 30 31 33—34
Genetic maps and mapping, markers in 31
Genetic markers 31 34 42
Genetics 5—7
Genotype 38 40
Geometry 166 203 210 211 220 223
Geometry, descriptors and methods 155—163 (see also “Topology”)
Global alignment 5 58—64 94—99
Global alignment, maximum-scoring 63
| Graph theory 46 51
Guanine (G) 8 9 99
Haldane mapping function 29 41
Helical periodicity 154
Helix 8 9 153
Helix, destabilization 184 188 196
Heterozygotes 6 16 31
Heuristic algorithms 82—84
Hierarchical condensation methods 248—251
Histones 154 175
HIV protease structure 254—255
Homeomorphisms 212—213
Homology modeling 252
Homozygotes 6 31
Human genome project 18—22 26
Hydrophilic side chains 244 253 263
Hydrophobic side chains 244 245 253
Hydrophobicity 4
In vitro assays 3
Incomplete penetrance 31 33 34
Independent assortment 29
Indexing, of databases 87
Infmitely-many-sites/alleles model 122 124 125 127—130
Isomerases 238
K-allele model 130—132
K-best alignments 76—78
kDNA (kinetoplast DNA) 231
Kingman’s subadditive ergodic theorem 97
Knot theory 212 (see also “Tangles and knots”)
Large Deviation Theory of Diffusion Processes 37—42
Levenshtein measure 73 87
LexA binding sites 198—199
Ligases 13
Likelihood methods 34—42 146—148
Linear DNA 155 156
Linking number (Lk) 155 157—158 163—164 173—174 181
Linking number (Lk), mini chromosomes 175 177
Linking number (Lk), surface 167—171 173—174
Linking number (Lk), topoisomerase reactions 164—166
Local alignment 5 65—70 99—106
Longest common subsequence 99
Macromolecules 3
Mapping see “Genetic maps and mapping” “Physical “Restriction “Sequencing
markers see “Genetic markers”
Markov models, processes 36 146—147 249
Maximum Likelihood Estimation 34—35
Maximum likelihood estimation, and efficient algorithms 35—36
Maximum likelihood estimation, and statistical significance 37—42
Measure-valued diffusions 148
Membrane-bound transporters 17—18 20
Mendelian genetics 5—7 27 31
Min (multiple intestinal neoplasia) trait 38—39
Minichromosomes 174—177
Mirror images 213—215
Mismatch ratio 86
Mitochondrial DNA (mtDNA) 115—116 117 118 135 148—149 204
mobius 143 181
Molecular biology, overview 7—12
Monte Carlo methods 146—147 149 241
Morgans 28
mRNA (messenger RNA) 9 12 92
Multiple alignments 73—76
Multiple minima problem 241
Mutation see “DNA polymorphisms and mutations”
Myoglobin 265—266
Native American population studies 116 117
Neighborhood concept 83
Neural networks 259—263
Nonadditive scoring schemes 87
Nuclear magnetic resonance (NMR) 203 240
Nucleic acids 3
Nucleosomes 154 166 174—177
nucleotides 8 57 118 204
Nucleotides, distances 29 81
Oncogenes 58 91 196
Ornstein — Uhlenbeck process 41
Overwinding 154
Packing density 252
Palindromes 87
Papillomavirus 196 199—200
Parallel computing 79—81 84 87
Penetrance 31 33 35
Phenocopy 34
Phenotype 38 40
Physical maps and mapping 17 19 26 29
Physical maps and mapping, fingerprinting methods 42—47
Phytogeny 73 76 87
PIR database 81
PLANS (Pattern Language for Amino and Nucleic Acids Sequences) 263—264
Platelet-derived growth factor (PDGF) 9
Plectonemic forms 154 156 169 170 215—216
Poisson distributions 144
Poisson distributions, Boltzmann equation 254
Poisson distributions, Dirichlet distribution 144
Poisson distributions, in coalescent trees 121 124—127
Poisson distributions, in sequence comparisons 29 100—104 108—110
Poly-adenylation 196
Polygenic inheritance 34
Polymerase chain reaction (PCR) 13 15 16 46
Polymorphism see “DNA polymorphisms and mutations”
Polyoma virus 196
Primers 13 15 16
Principle of optimality 63
Probabilistic combinatorics 136
Processing time see “Computing time and memory capacity”
Protein folding 5 12 236—248
Protein folding, hierarchical condensation methods 248—251 256—265
Protein folding, prediction of 5 254—255 265—266
Protein folding, threading methods 248—254
Proteins 3—5 7—8 57 92 “Protein “Sequence
Public databases see “Databases of DNA sequences”
Pure breeding 5
Purines (R) 99 117 200
Pyrimidines (Y) 99 117 118 123 128 200
QUEST systems 87
R-group 237
Rational tangles 218—221 228—229
RecA binding 198—199 211 227
Recessive traits 16
Recombinant DNA technology 13—16 17
Recombination 27—28 205 213 225—230
Recombination, frequency 28—30 31 35
Recombination, site-specific 207—212 222—225
Replication processes 92 154 179—180 183 204
Resolvase 213 225—230
Restriction enzymes 13
Restriction fragment lists 45—46
Restriction maps 44—45 87
Ribosomes 9 10 12 92
RNA (ribonucleic acid) 9 179 196 237
RNA (ribonucleic acid), evolutionary analysis 92—93 106—107 110—112
RNA (ribonucleic acid), polymerase 9
RNA (ribonucleic acid), rRNA 92 93 106 107 110 112 “tRNA”)
Rule-based methods 263—264
Scoring schemes, gap cost penalties 70—72
Scoring schemes, global alignments 59—64
Scoring schemes, K-best alignments 76—78
Scoring schemes, local alignments 65—68
Scoring schemes, minimal cost alignments 72—73
Scoring schemes, multiple alignments 74—76
Scoring schemes, nonadditive 87
Scoring schemes, unit-cost 58—59 86
Sedimentation rate 100
self-replication 92
Sequence similarity, and comparison 56—58 86—87 91 199
Sequence similarity, approximate pattern matching 78—79 86
Sequence similarity, database searches 78—79 82—86 87 91—92 94
Sequence similarity, difference measures 72—73
Sequence similarity, gap cost penalties 70—72
Sequence similarity, global alignment 5 58—64 94—99
|
|
|
| Реклама |
|
|
|


 |
|
О проекте
|
|
О проекте