|
|
 |
| Авторизация |
|
|
|
| Поиск по указателям |
|
|
|
|
|
|
|
 |
|
|
|
| Bourne P.E., Weissig H. — Structural bioinformatics |
|
|
|
| Предметный указатель |
"Frozen approximation", fold recognition, threading algorithms 534—535
"Frozen approximation", fold recognition, threading errors 538—539
"Kissing-loop" structure, mismatched/bulged RNA 62—63
"Knobs-into-holes" geometry, one-dimensional secondary structure prediction 561—562
"Thawing" approximation, fold recognition, threading errors 538—539
"Training set" proteins, structural bioinformatics 6
"Twilight zone" sequencing, fold recognition, protein sequence analysis 528—529
"Twilight zone" sequencing, one-dimensional secondary structure prediction 559—562
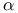 -helices, high-throughput crystallographic analysis, electron density map interpretation 80 -helices, high-throughput crystallographic analysis, electron density map interpretation 80
-helices, SCOP hierarchical classification 240-241
-helices, secondary protein structure, assignment protocols, DEFINE algorithm 345
-helices, secondary protein structure, assignment protocols, Dictionary of Secondary Structure of Proteins (DSSP) techniques 344
-helices, secondary protein structure, assignment protocols, P-Curve assignment scheme 345—346
-helices, secondary protein structure, assignment protocols, STRIDE protocol 344—345
-helices, secondary protein structure, properties 22—24
-helices, secondary protein structure, three-dimensional models 21
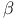 sheets, high-throughput crystallographic analysis, electron density map interpretation 80 sheets, high-throughput crystallographic analysis, electron density map interpretation 80
sheets, SCOP hierarchical classification 240—241
sheets, secondary protein structure, assignment protocols 345—346
sheets, secondary protein structure, assignment protocols, DEFINE algorithm 345
sheets, secondary protein structure, assignment protocols, Dictionary of Secondary Structure of Proteins (DSSP) techniques 344
sheets, secondary protein structure, assignment protocols, STRIDE protocol 344—345
sheets, secondary protein structure, properties 24
sheets, secondary protein structure, three-dimensional models 21
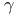 perturbation method, high-throughput crystallographic analysis, density modification 78 perturbation method, high-throughput crystallographic analysis, density modification 78
2,2-Dimethylsilapentane-5-sulfonic acid (DSS), macromolecular structure, NMR spectroscopy 93—94
5S RNA, all-atom contacts 313—316
A-DNA, base pair geometry 47—49
A-DNA, Nucleic Acid Database (NDB) data 206—210
A-DNA, pucker structures 56 58—59
A-RNA, duplex structure 60-62
A-RNA, hammerhead ribozymes 61 64
A-RNA, mismatched/bulged RNA 62—63
A-RNA, transfer RNA (tRNA) structure 61 63
Ab initio fold prediction, applications 549—551
Ab initio fold prediction, applications, genome annotation 549—550
Ab initio fold prediction, applications, structural genomics 550-551
Ab initio fold prediction, Critical Assessment for Structure Prediction (CASP), comparative modeling 502—503
Ab initio fold prediction, Critical Assessment for Structure Prediction (CASP), fold recognition 503
Ab initio fold prediction, Critical Assessment for Structure Prediction (CASP), novel fold recognition 503—504
Ab initio fold prediction, Critical Assessment for Structure Prediction (CASP), research background 499—501
Ab initio fold prediction, Critical Assessment for Structure Prediction (CASP), summary of progress 501—502
Ab initio fold prediction, docking and ligand design, molecular mechanics scoring functions, charge representation 457—459
Ab initio fold prediction, future research 551—552
Ab initio fold prediction, homology modeling 510
Ab initio fold prediction, homology modeling, loop regions 514
Ab initio fold prediction, physics principles and 531 533
Ab initio fold prediction, polypeptide chain representations 546—547
Ab initio fold prediction, potentials categories 547—548
Ab initio fold prediction, protein function identification 396—397
Ab initio fold prediction, search methods 548—549
Ab initio fold prediction, structural assignment, Coulomb hydrogen bond calculation 343
Ab initio fold prediction, structural bioinformatics 8
Ab initio fold prediction, structural bioinformatics, prediction techniques 10
Ab initio fold prediction, theoretical background 545
Access issues, Nucleic Acid Database (NDB) 203—204
Access issues, Nucleic Acid Database (NDB), mirror sites 205—206
Access issues, one-dimensional secondary structure prediction 572
Access issues, Protein Data Bank (PDB) 189—194
Access issues, Protein Data Bank (PDB), application web access 193—194
Access issues, Protein Data Bank (PDB), database architecture 190-191
Access issues, Protein Data Bank (PDB), ftp access 194
Access issues, Protein Data Bank (PDB), user web access 191—193
Access issues, quality assurance information 296—298
Accessible surface area (ASA), docking and ligand orientation 453—454
Actin filaments, electron cryomicroscopy, protein dynamics 124—125
Actin filaments, electron cryomicroscopy, three-dimensional reconstruction 121
Active sites, secondary protein structure 24—28
Adaptive finite element discretization, electrostatic interactions, Poisson — Boltzmann equation (PBE) 433—435
ADME (absorption, distribution, metabolism, and excretion) modeling, docking and ligand design 468
ADME (absorption, distribution, metabolism, and excretion) modeling, drug modeling 490
ADMET (absorption, distribution, metabolism, excretion, and toxicology) modeling, drug bioinformatics, pharmaceutical models 479
Algorithm development, structural bioinformatics 4—6
Algorithm development, structural bioinformatics, structural assessment and evaluation 9
Aligned fragment pair (AFP), protein structure representation, combinatorial extension (CE) algorithm 324
Aligned fragment pair (AFP), structure comparison and alignment, CE algorithm optimization 325
Alignment see "Structure comparison and alignment"
Alignment algorithms, fold recognition, threading approximation 534—535
Alignment algorithms, homology modeling, template identification and alignment 510-511
Alp molecular switch, protein function identification, Mjo577 genome 400—401
Alpha/beta hydrolase fold, protein function identification 393—394
AM1—BCC model, docking and ligand design, molecular mechanics scoring functions 458—459
AMBER force fields, docking and ligand design, free energy binding 464
AMBER force fields, docking and ligand design, molecular mechanics scoring functions 458—459
AMBER force fields, nucleic acid chemical structure 42—45
Amino acid sequence, domain identification 380
Amino acid sequence, fold recognition, threading errors 537—539
Amino acid sequence, homology modeling 507—510
Amino acid sequence, one-dimensional secondary structure, prediction, theoretical background 558—562
Amino acid sequence, protein structure 16—20
Amino acid sequence, protein structure, amino acid structures 16—17
Amino acid sequence, protein structure, peptide bond 17—20
Analogue structures, computer-aided drug design (CADD) 444—445
Analogue structures, protein function identification 395—396
Angle-distance hydrogen bond assignment, secondary protein structures 341—342
Angular reconstitution, electron cryomicroscopy, single-particle analysis 122
Annotation of data, Protein Data Bank (PDB) information 184—186
ANOLEA program, error estimation and precision, atom-atom contacts 294
Anomalous diffraction, high-throughput, crystallographic analysis, macromolecular structures 77
Anti conformation, A-DNA 56 58—59
Anti conformation, sugar phosphate backbone conformation 53—55
Anti conformation, Z-DNA 59
Antiparallel structures, -sheets, secondary protein structure 24
Application program interface (API), format and protocols 178
Application program interface (API), Protein Data Bank (PDB) architecture, application web access 193—194
Application web access, Protein Data Bank (PDB) 193—194
AQUA program, protein structure, validation 102—103
Aquaporin, electron cryomicroscopy, three-dimensional crystalline arrays 121
Asn/Gln flips, all-atom contact analysis 311—316
Assay design, drug bioinformatics, lead identification 487
Assembly mechanisms, quaternary protein structure 35
ASTRAL compendium, sequence and structure relationships data 220-221
Atom-atom contacts, domain identification 365—367
Atom-atom contacts, error estimation and precision 292—294
Atom-atom contacts, homology modeling validation 519
Atom-atom contacts, structure validation 303—304
Atom-atom contacts, structure validation, current facilities and applications 311—317
Atom-atom contacts, structure validation, protocols 305—307
Atom-atom contacts, structure validation, vs. traditional criteria 308—311
ATOM/HETATM data, ASTRAL, compendium secondary data 220—221
Atomic nomenclature, Protein Data Bank (PDB) data validation and annotation 186
Atomic positions, homology model optimization 516—518
Atomic positions, macromolecular Crystallographic Information File (mmCIF) 173—175
Atomic solvation parameters (ASP), docking and ligand design, solvent representation 460—461
Atoms in molecules (AIM) theory, docking and ligand design, molecular mechanics scoring functions 458—459
ATPases, drug bioinformatics, target druggability 479—480
AutoDep Input Tool (ADIT), Nucleic Acid Database (NDB) validation 201—202
AutoDep Input Tool (ADIT), nucleic acid structures, error estimation and precision 294—295
AutoDep Input Tool (ADIT), Protein Data Bank (PDB), data acquisition and deposition 182 187
AUTODOCK software, ligand orientation 447—448
Automation techniques, comparative modeling sources, Swiss-Model database 228
Automation techniques, high-throughput crystallographic analysis, disorder 83
Automation techniques, high-throughput crystallographic analysis, noncrystallographic symmetry 82—83
Automation techniques, high-throughput crystallographic analysis, research background 76
Automation techniques, secondary protein structure, assignment comparisons 347—349
Automation techniques, secondary protein structure, structure assignment 340—341
Average positional error, x-ray, crystallography models 281
AVS software, macromolecular visualization 144
B-DNA, base pair geometry 47—49
B-DNA, duplexes 55—59
B-DNA, Nucleic Acid Database (NDB) data 206—210
B-DNA, structural analysis 42
B-factors models, all-atom contact analysis 308—311
B-factors models, quality assurance 272—273
B-factors models, x-ray crystallography models, atomic B-factor errors 281
B-factors models, x-ray crystallography models, uncertainty estimation 275—277
Back-calculation techniques, error estimation and precision, NMR models 283—284
Backbone conformation, ab initio fold prediction, polypeptide chains 546—547
Backbone conformation, all-atom contact analysis 310—316
Backbone conformation, homology modeling 508—510 513
| Backbone conformation, homology modeling, loop regions 513—514
Backbone conformation, homology modeling, side-chain conformations 515—516
Bacterial hydrolase, protein function identification 401—402
Ball-and-stick model, -helices 22—24
Ball-and-stick model, electrostatic interactions, Poisson — Boltzmann equation (PBE) 430—432
Base pairing, DNA duplexes 55—59
Base pairing, geometry 45—49
Base pairing, geometry, buckle 46—47
Base pairing, geometry, helical twist 49
Base pairing, geometry, inclination 47
Base pairing, geometry, propeller twist 46—47
Base pairing, geometry, roll 49
Base pairing, geometry, tilt 49
Base pairing, geometry, X and Y displacements 47—48
Base pairing, nucleic acid chemical structure 42—45
Base pairing, Nucleic Acid Database (NDB) data 208—210
Base pairing, sugar phosphate backbone conformation 50—55
Bidirectional recurrent neural networks (BRNN) complex, one-dimensional secondary structure prediction 561—562
Bifunctional proteins, IMPase structure 402
BIND database, protein-protein interaction prediction 417
Binding sites, docking and ligand design, complex formation 450—454
Binding sites, docking and ligand design, free energies 463—464
Binding sites, docking molecules 445
Binding sites, drug bioinformatics, target druggability 479—481
Binding sites, fold recognition, convergent evolution 524
Bioinformatics see also "Structural bioinformatics"
Bioinformatics, defined 3—7
Bioinformatics, SCOP organization and capabilities 244—246
Biological Macromolecule Crystallization Database (BMCD), primary data sources 218—219
Biological Macromolecule Crystallization Database (BMCD), Protein Data Bank (PDB) architecture 191
Biology-based fold recognition, molecular evolution, sequence similarity and homology 527
Biology-based fold recognition, protein families and multiple alignments 529—531
Biology-based fold recognition, protein sequence analysis 527—529
Biology-based fold recognition, theoretical background 526
BioMagResBank (BMRB), macromolecular structure, NMR spectroscopy 91—94
BioMagResBank (BMRB), macromolecular structure, validation 103
Biopolymers, electrostatic interactions 426
BioSync dictionary, format and content 175
Birdwash toolkit, macromolecular visualization 149
BLAST search techniques, fold recognition, protein sequence analysis 528—529
BLAST search techniques, homology modeling, template identification and alignment 510—511
BLAST search techniques, MacroMolecular Database (MMDB) 221—222
BLAST search techniques, SCOP organization and capabilities 242—244
BLAST search techniques, Swiss-Model database 228
Blue Gene computer, homology model optimization 518
Bobscript, macromolecular visualization 143
Boltzmann constant, docking and ligand design 452—454
Boltzmann constant, electrostatic interactions, Poisson equation 429—430
Bond distances, all-atom contact analysis 310—311
Born ion model, electrostatic interactions 427
Boundary identification, CATH domain structure database 258
Brownian dynamics, electrostatic interactions 427
Brunger's free R-tactor, x-ray crystallography, error estimation and precision 280—281
Buckle sign, base pair geometry 46—47
Bulged RNA, structural characteristics 62—63
C-alpha only structures, domain identification 364—365
C-alpha only structures, domain identification, amino acid sequence 380
C-alpha only structures, error estimation and precision 294
C2 domains, electrostatic interactions 427—428
Calcium complex, macromolecular structure, NMR spectroscopy 95—96
Cambridge Accord conventions, base pair geometry 45—49
Cambridge Crystallographic Data Center (CCDC) 219—220
Cambridge Structural Database (CSD), high-throughput crystallographic analysis 76
Cambridge Structural Database (CSD), macromolecular structure, validation 102—103
Cambridge Structural Database (CSD), primary information sources 219—220
Capsid structures, electron cryomicroscopy, single-particle analysis 122
Carbohydrate modification, tertiary protein structure 30
Carbon-13 nuclei, macromolecular structure, NMR spectroscopy 90—91
Carboxyl group (COOH), amino acid sequence 16—17
Cartesian meshes, electrostatic interactions, Poisson — Boltzmann equation (PBE) 432—433
CATH (Class, Architecture, Topology, and Homology) domain structure database, boundary identification 258
CATH (Class, Architecture, Topology, and Homology) domain structure database, comparison with SCOP and DALI 247—248
CATH (Class, Architecture, Topology, and Homology) domain structure database, domain identification, assignment criteria 377—379
CATH (Class, Architecture, Topology, and Homology) domain structure database, domain identification, second generation assignment algorithms 374—377
CATH (Class, Architecture, Topology, and Homology) domain structure database, fold recognition, limitations 524—525
CATH (Class, Architecture, Topology, and Homology) domain structure database, GENE3D resource 260—261
CATH (Class, Architecture, Topology, and Homology) domain structure database, historical development 248—252
CATH (Class, Architecture, Topology, and Homology) domain structure database, homologous structures, sequence-based protocols 253—255
CATH (Class, Architecture, Topology, and Homology) domain structure database, homologous structures, structure-based methods 255—257
CATH (Class, Architecture, Topology, and Homology) domain structure database, homologous structures, superfamily dictionaries 259—260
CATH (Class, Architecture, Topology, and Homology) domain structure database, homologous structures, superfamily sequence relatives 260
CATH (Class, Architecture, Topology, and Homology) domain structure database, multiple structure alignments, 3D templates 257
CATH (Class, Architecture, Topology, and Homology) domain structure database, population statistics, folds in architectures 263—264
CATH (Class, Architecture, Topology, and Homology) domain structure database, population statistics, superfamily/family folds 264—267
CATH (Class, Architecture, Topology, and Homology) domain structure database, protein fold space mapping 330—332
CATH (Class, Architecture, Topology, and Homology) domain structure database, protein function identification 397
CATH (Class, Architecture, Topology, and Homology) domain structure database, server applications 263—267
CATH (Class, Architecture, Topology, and Homology) domain structure database, structural/phylogenctic identification 249—260
CATH (Class, Architecture, Topology, and Homology) domain structure database, update protocols 262—263
CATH (Class, Architecture, Topology, and Homology) domain structure database, web site and server protocols 261—263
CE database, Protein Data Bank (PDB) architecture 191
Cell-free protein production, NMR spectroscopy 104—105
Cellular genomes, amino acid sequence 17
Cellular genomes, electrostatic interactions, Poisson — Boltzmann equation (PBE) 435—436
Change-coupled device (CCD), electron cryomicroscopy, electron tomography 123
Change-coupled device (CCD), electron cryomicroscopy, optics and image formation 116—119
Charge representation, docking and ligand design, molecular mechanics scoring functions 457—459
Charged amino acids, side chain sequence 17
CHARMM force fields, nucleic acid chemical structure 42—45
Chemical leads, drug bioinformatics, identification 487—488
Chemical leads, drug bioinformatics, optimization 489—490
Chemical libraries, drug bioinformatics 488
Chemical shift protocols, macromolecular structure, concerted techniques 106
Chemical shift protocols, macromolecular structure, NMR spectroscopy 92—94
Chemical shift protocols, macromolecular structure, validation 103
Chemical shift protocols, protein structure, NMR spectroscopy 100—102
Chime browser, web-based visualization techniques 146—148
Chimera software, macromolecular visualization 143—144
Clash score, all-atom contact analysis 308—311
Clash score, all-atom contact analysis, PDB files 311—316
Clashlistcluster script, all-atom contacts 313—316
Classification protocols, structural bioinformatics 10
CLIX, docking and ligand site characterization 445—446
Close contacts, Protein Data Bank (PDB) data validation and annotation 186
CLUSTALW program, homology modeling, multiple sequence alignment 512—513
CLUSTALW program, told recognition, protein sequence analysis 528—529
CNS program, protein structure, validation 103
Co-localization, quaternary protein structure 35
Coevolution, protein-protein interaction prediction 411
Coil regions, secondary protein structure 24—28
Coiled-coil predictions, one-dimensional secondary structure prediction 561—562
COILS program, one-dimensional secondary structure prediction 561—562
Combinatorial brand-and-bound minimization algorithm, fold recognition, ahreading approximations 534—535
Combinatorial calculation, docking and ligand design, receptor flexibility 461
Combinatorial calculation, docking and ligand design, sampling issues 461
Combinatorial extension (CE) algorithm, multiple structure alignments 329—330
Combinatorial extension (CE) algorithm, protein fold space mapping 330—332
Combinatorial extension (CE) algorithm, protein kinase alignments 327—328
Combinatorial extension (CE) algorithm, statistical testing 326
Combinatorial extension (CE) algorithm, structure comparison and alignment 323—327
Combinatorial extension (CE) algorithm, structure comparison and alignment, optimization 325
Combinatorial extension (CE) algorithm, structure comparison and alignment, protein structure representation 324
Combinatorial subunits, quaternary protein structure 35
Common Gateway Interface (CGI), Protein Data Bank (PDB) architecture 191
Common Gateway Interface (CGI), Protein Data Bank (PDB) architecture, application web access 193—194
Common Object Request Broker Architecture (CORBA), database interoperability 231
Common Object Request Broker Architecture (CORBA), format and protocols 178
Common Object Request Broker Architecture (CORBA), Protein Data Bank (PDB), future applications 196
Comparative modeling, Critical Assessment for Structure Prediction (CASP), procedures 502—503
Comparative modeling, Critical Assessment for Structure Prediction (CASP), research background 499—501
COMPARER system, comparison algorithm optimization 325—326
COMPARER system, protein structure representation 325
COMPARER system, statistical testing 326
Comparison algorithms, structure comparison arid alignment 325—326
Complex reassembly, docking and ligand design 462—464
Complex reassembly, docking and ligand design, free energies of binding 463—464
Complex reassembly, docking and ligand design, geometric issues 462—463
Complex reassembly, docking and ligand design, ranker energy ordering 463
Complex reassembly, docking and ligand design, success/failure ratios 463
Computational techniques, drug bioinformatics, target triage 484—486
|
|
|
| Реклама |
|
|
|


 |
|
О проекте
|
|
О проекте