Авторизация
Поиск по указателям
Pearson R.K. — Mining imperfect data: dealing with contamination and incomplete records
Обсудите книгу на научном форуме Нашли опечатку?
Название: Mining imperfect data: dealing with contamination and incomplete recordsАвтор: Pearson R.K. Аннотация: Data mining is concerned with the analysis of databases large enough that various anomalies, including outliers, incomplete data records, and more subtle phenomena such as misalignment errors, are virtually certain to be present. Mining Imperfect Data: Dealing with Contamination and Incomplete Records describes in detail a number of these problems, as well as their sources, their consequences, their detection, and their treatment. Specific strategies for data pretreatment and analytical validation that are broadly applicable are described, making them useful in conjunction with most data mining analysis methods. Examples are presented to illustrate the performance of the pretreatment and validation methods in a variety of situations; these include simulation-based examples in which "correct" results are known unambiguously as well as real data examples that illustrate typical cases met in practice.
Язык: Рубрика: Математика /Статус предметного указателя: Готов указатель с номерами страниц ed2k: ed2k stats Год издания: 2005Количество страниц: 316Добавлена в каталог: 23.10.2010Операции: Положить на полку |
Скопировать ссылку для форума | Скопировать ID
Предметный указатель
23 70 73—76 88 274 Akaike information criterion (AIC) 114 Autocorrelation 8 241 Auxiliary knowledge 138—139 222 Bagplot 204 Balanced 186 Binary variable 266—268 Biplots 205 Bootstrap 208 210 Bootstrap, moving blocks 210 Boxplot 26 178 193 Boxplot, asymmetric outlier rule 78 Boxplot, clockwise bivariate 205 Boxplot, definition and illustration 4—7 Boxplot, outlier rule 70 73 77—78 88 Boxplot, symmetric outlier rule 78 Breakdown, definition 19 Breakdown, finite sample 76 Breakdown, how high? 275 Breakdown, kurtosis estimator 20 Breakdown, masking 76 Breakdown, maximum possible 19 Breakdown, mean 20 Breakdown, median 19 Breakdown, swamping 77 Caliper 179 Canonical correlation analysis (CCA) 130 Chaos 168 Cluster analysis 97 174 183 192 230—231 276 Cluster analysis, balanced 231 Collinearity 58 97—100 Collinearity, definition 11 Computational negative controls (CNC) 219 244—251 Constraints 58—60 Contamination, definition 19 Contamination, typical 19 Continuity, absolute 194 Convex function 163 Convex polytope 169 Correlation coefficient 196 Correlation coefficient, overlapping subsets 212—213 Correlation coefficient, product-moment 47—48 Correlation coefficient, Spearman rank 50—51 197 248 280 Correlation coefficient, zero 165 Covariance matrix, definition 48 Covariance matrix, indefinite 108 Cross-correlation 241—244 Cross-correlation, rank-based 248—251 Crossing 187 Data depth 134—138 228 Data distribution, asymmetric 36 90 277—283 Data distribution, beta 232 Data distribution, chi-square ( 129 Data distribution, exponential 278 Data distribution, gamma 194 278 Data distribution, Gaussian (normal) 74 219 278 Data distribution, Student’s t 233 Data distribution, uniform 167 194 Data distribution, unimodal 36 Data-based prototyping 270 Dataset, Brownlee 272 Dataset, CAMDA normal mouse 16—17 24 54 138—139 283 Dataset, catalyst 87—88 Dataset, flow rate 88—90 Dataset, industrial pressure 90—91 235—237 254—263 Dataset, Michigan lung cancer 263—268 Dataset, microarray 1 2 37—39 95—96 126 Dataset, storage tank 237—251 DataSpheres 228 Deadzone nonlinearity 65 Deletion diagnostics 30 213—217 241 244 274 Deletion diagnostics, successive 216 Descriptor 26 178 179 192—193 Descriptor, figure-of-merit 192 199—201 Distance-distance plot 129 Dotplot 193 Empirical quantiles 5 Equivariant 155 Equivariant, affine 156 Equivariant, regression 156 Equivariant, scale 156 Exact fit property (EFP) 141 Exchangeability 25 32 178—180 199 219 Expectation Maximization (EM) algorithm 203 Experimental design 188—190 Extended data sequence 254 Extreme studentized deviation (ESD) 74 Forward search 133 Fouling 243 Function differentiable 151 157 Functional equation 144—159 Functional equation, bisymmetry 154 Functional equation, Cauchy’s basic 144 Functional equation, Cauchy’s exponential 145 Functional equation, Cauchy’s logarithmic 145 Functional equation, Cauchy’s power 146 Galton’s skewness measure 196 278 Galton’s skewness measure, definition 44 Galton’s skewness measure, outlier-sensitivity 44 General position 156 158 Generalized sensitivity analysis (GSA) 25—31 177—201 Giant magnetostriction 13 Gini’s mean difference 280 Gross errors 33 52—53 Hampel filter 122—124 Hampel filter, iterative 202 Hampel identifier 24 35 70 73 76—77 88 Hard saturation nonlinearity 64 Heuristic 177 Homogeneity 134 144 147—149 151 Homogeneity, generalized 147 Homogeneity, order c 147 Homogeneity, order zero 149 Homogeneity, positive 147 Hotelling’s 129 Ideal quantizer 64 Idempotent 9 60 62—66 118 120 Implosion 77 Imputation 23 60 Imputation, cold-deck 105 Imputation, hot-deck 105 Imputation, mean 103 Imputation, multiple 105—108 276 Imputation, single 103—105 276 Inequality 159—166 Inequality, arithmetic-geometric mean (AGM) 154 161—162 Inequality, Cauchy — Schwarz 160 Inequality, Chebyshev 159 Inequality, Jensen 163 Interquartile distance (IQD), comparisons 29—30 Interquartile distance (IQD), definition 7 24 Interquartile distance (IQD), outlier-sensitivity 43 Interval arithmetic 168 Inward testing procedures 202 Jackknife 214—215 Kurtosis variability 232—235 Kurtosis, beta distribution 232 Kurtosis, breakdown point 20 Kurtosis, definition 5 Kurtosis, estimator 5 Kurtosis, lower bound 18 232 Kurtosis, outlier-sensitivity 18 Kurtosis, Student’s t 234 Leptokurtic 233 Literary Digest 61 Location-invariance 149—152 Lowess smoother 223 254 MA plot 37 126 Mahalanobis distance 39 128—131 Mahalanobis distance, definition 47 Mann — Whitney test 46 Martin — Thomson data cleaner 115 275 Masking 74 274 Mean, arithmetic 154 157 161—162 Mean, bounds 163—166 Mean, generalized 161 Mean, geometric 154 161—162 Mean, harmonic 154 162 165 Mean, outlier-sensitivity 20 41—43 Mean, quasi-arithmetic 154 Mean, quasilinear 154—155 161 Mean, versus median 20—23 Mean, zero breakdown 20 Median absolute deviation (MAD), comparisons 29—30 Median absolute deviation (MAD), definition 24 Median Filter 117 Median filter, center-weighted (CWMF) 118—122 187 Median versus mean 20—23 Median, breakdown 19 Median, characterization 157 Median, definition 5 Median, deletion-sensitivity 21 Median, multivariate 134—138 Median, outlier-sensitivity 43 Median, smallest bias 275 Metaheuristic 177 178 Mice and elephants 211 Microarray 1 2 16—17 37 54 Midmean 28 256 275 Minimum covariance determinant (MCD) 128 Minimum volume ellipsoid (MVE) 131 Minkowski addition 168 Misalignment, CAMDA dataset 16—17 25 Misalignment, caused by missing data 55 Misalignment, caused by software errors 56 Misalignment, causes 54—58 Misalignment, consequences 9—11 Misalignment, definition 9 Misalignment, detection 283—286 Misalignment, prevalence 274 Missing data from file merging 66—67 Missing data, coded 33 71 Missing data, definition 7 Missing data, disguised 8 33 60 71 Missing data, ignorable 7 60 Missing data, imputation see "Imputation" Missing data, missing at random (MAR) 277 Missing data, missing completely at random (MCAR) 277 Missing data, modelled as zero 26 Missing data, nonignorable 7 52 60—61 102 103 106 276 277 Missing data, representation 61 271 Missing data, treatment strategies 60 102—110 Modal skewness 280 Mode estimator 279 Modified 134 Monotone missingness 107 Moving-window characterizations 252—263 Nesting 187 Niche 16 Noise 96—97 Noise versus anomalies 33 Nominal variable 264 Nonadditivity model 229 Noninformative variable 25 93—102 276 Noninformative variable, application-specific 95 Noninformative variable, external 94 Noninformative variable, inherent 94 Nonlinear digital filters 117 202 Nonsampling errors 52 Norm 179 NULLs 61—63 Occam’s hatchet 98 Occam’s razor 98 Order statistics definition 5 Ordinal variable 264 Outlier model, additive 70 115 Outlier model, contaminated normal 72 79 Outlier model, discrete mixture 71 Outlier model, point contamination 71 Outlier model, Poisson 112 Outlier model, replacement 71 Outlier model, slippage 73 Outlier model, univariate 70—73 Outlier, common mode 53 237 277 Outlier, definition 2 23 Outlier, detection 23 69—91 Outlier, good 13—16 Outlier, isolated 112 277 Outlier, lower 36 Outlier, multivariate 3 9 24 37—40 124—138 Outlier, orientation 39 Outlier, patchy 112 119 277 Outlier, sources 52—53 Outlier, time-series 40 110—124 Outlier, univariate 2 3 9 11 23—24 34—37 69—91 Outlier, upper 36 Outlier-sensitivity, Galton’s skewness measure 44 Outlier-sensitivity, interquartile distance (IQD) 43 Outlier-sensitivity, kurtosis 18 Outlier-sensitivity, Mann — Whitney test 46 Outlier-sensitivity, mean 20 41—43 Outlier-sensitivity, median 43 Outlier-sensitivity, skewness 43 Outlier-sensitivity, t-test 45 Outlier-sensitivity, variance 43 Oversampling 231 Permutation invariance 151 154 157 Platykurtic 232 Plug flow model 242 Poisson’s ratio 13 Preface ix Princeton Robustness Study 20 73 152 194 275 278 Principal component regression (PCR) 130 Principal components analysis (PCA) 130 205 Pseudonorm 158 Pyramids 228 Quantile-quantile (Q-Q) plot 194—195 219 220 235 Random subsets 26 208—212 238 Random subsets, disjoint 208—209 Random subsets, limitations 270 Ranking populations 228 Regression, comparisons 272 Regression, depth-based 137—138 Regression, iteratively reweighted least squares 201 Regression, least median of squares (LMS) 22 275 Regression, M-estimators 274 Regression, ordinary least squares (OLS) 98—102 188—189 215 274 Regression, set-theoretic 169 Relational database 57 95 Resistant 25 Root Mean Square (RMS) 120 Root sequence 115 118—120 Sampling bias 60 Sampling, Bernoulli 224 Sampling, cluster 230 Sampling, importance 211 Sampling, model-based 223 Sampling, Poisson 225 Sampling, probability proportional-to-size 225 Sampling, random with replacement 208 Sampling, random without replacement 208 Sampling, scheme 26 178 190—191 Sampling, sequential 230 Sampling, stratified 225 Sampling, subset-based 178 207—268 Sampling, systematic 223 Scenario 25 178 180—186 Set-valued variables 108 166—172 Shift errors 283 Silhouette coefficient 97 192
Реклама



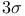 edit rule
edit rule 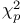 )
) 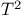 statistic
statistic 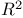 statistic
statistic  |
|
О проекте
|
|
О проекте