|
Электронная библиотека Попечительского совета механико-математического факультета Московского государственного университета |
| Главная Ex Libris Книги Журналы Статьи Серии Каталог Wanted Загрузка ХудЛит Справка Поиск по индексам Поиск |



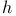 -projection
-projection 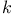 -nearest neighbor algorithm
-nearest neighbor algorithm 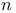 -grams
-grams 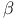 -mixing
-mixing 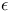 -insensitive loss function
-insensitive loss function 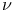 -support vector classifiers
-support vector classifiers 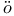 m approximation
m approximation
© Электронная библиотека попечительского совета мехмата МГУ, 2004-2025 |
|
О проекте |
|
О проекте
|