Powell W.B. — Approximate dynamic programming: Solving the curses of dimensionality
Обсудите книгу на
Нашли опечатку? Выделите ее мышкой и нажмите Ctrl+Enter
Название: Approximate dynamic programming: Solving the curses of dimensionality
Автор: Powell W.B.
Аннотация:
A complete and accessible introduction to the real-world applications of approximate dynamic programming
With the growing levels of sophistication in modern-day operations, it is vital for practitioners to understand how to approach, model, and solve complex industrial problems. Approximate Dynamic Programming is a result of the author's decades of experience working in large industrial settings to develop practical and high-quality solutions to problems that involve making decisions in the presence of uncertainty. This groundbreaking book uniquely integrates four distinct disciplines—Markov design processes, mathematical programming, simulation, and statistics—to demonstrate how to successfully model and solve a wide range of real-life problems using the techniques of approximate dynamic programming (ADP). The reader is introduced to the three curses of dimensionality that impact complex problems and is also shown how the post-decision state variable allows for the use of classical algorithmic strategies from operations research to treat complex stochastic optimization problems.
Designed as an introduction and assuming no prior training in dynamic programming of any form, Approximate Dynamic Programming contains dozens of algorithms that are intended to serve as a starting point in the design of practical solutions for real problems. The book provides detailed coverage of implementation challenges including: modeling complex sequential decision processes under uncertainty, identifying robust policies, designing and estimating value function approximations, choosing effective stepsize rules, and resolving convergence issues.
With a focus on modeling and algorithms in conjunction with the language of mainstream operations research, artificial intelligence, and control theory, Approximate Dynamic Programming:
Models complex, high-dimensional problems in a natural and practical way, which draws on years of industrial projects
Introduces and emphasizes the power of estimating a value function around the post-decision state, allowing solution algorithms to be broken down into three fundamental steps: classical simulation, classical optimization, and classical statistics
Presents a thorough discussion of recursive estimation, including fundamental theory and a number of issues that arise in the development of practical algorithms
Offers a variety of methods for approximating dynamic programs that have appeared in previous literature, but that have never been presented in the coherent format of a book
Motivated by examples from modern-day operations research, Approximate Dynamic Programming is an accessible introduction to dynamic modeling and is also a valuable guide for the development of high-quality solutions to problems that exist in operations research and engineering. The clear and precise presentation of the material makes this an appropriate text for advanced undergraduate and beginning graduate courses, while also serving as a reference for researchers and practitioners. A companion Web site is available for readers, which includes additional exercises, solutions to exercises, and data sets to reinforce the book's main concepts.



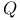 -leaming
-leaming 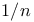
 |
|
О проекте
|
|
О проекте