
Обсудите книгу на
Нашли опечатку?
Выделите ее мышкой и нажмите Ctrl+Enter
|
Название: Dynamic programming and optimal control (Vol. 2)
Автор: Bertsekas D.P.
Аннотация:
This is a modest revision of Vol. 2 of the 1995 best-selling dynamic programming 2-volume book by Bertsekas. DP is a central algorithmic method for optimal control, sequential decision making under uncertainty, and combinatorial optimization. The treatment focuses on basic unifying themes and conceptual foundations. It illustrates the power of the method with many examples and applications from engineering, operations research, and economics. Among its special features, the book: (a) provides a unifying framework for sequential decision making (b) develops the theory of deterministic optimal control including the Pontryagin Minimum Principle © describes neuro-dynamic programming techniques for practical application of DP to complex problems that involve the dual curse of large dimension and lack of an accurate mathematical model (d) provides a comprehensive treatment of infinite horizon problems in the second volume, and an introductory treatment in the first volume (e) contains many exercises, with solutions of the most theoretical ones posted on the book's www page.
Язык: 
Рубрика: Computer science/
Статус предметного указателя: Готов указатель с номерами страниц
ed2k:
Год издания: 1995
Количество страниц: 292
Добавлена в каталог: 04.12.2005
Операции: Положить на полку |
Скопировать ссылку для форума | Скопировать ID
|

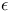 -optimal policy
-optimal policy  |
|
О проекте
|
|
О проекте