Suykens J.A.K., Horvath G., Basu S. — Advances in learning theory: methods, models and applications
Обсудите книгу на
Нашли опечатку? Выделите ее мышкой и нажмите Ctrl+Enter
Название: Advances in learning theory: methods, models and applications
Авторы: Suykens J.A.K., Horvath G., Basu S.
Аннотация:
In recent years, considerable progress has been made in the understanding of problems of learning and generalization. In this context, Intelligence basically means the ability to perform well on new data after learning a model on the basis of given data. Such problems arise in many different areas and are becoming increasingly important and crucial towards many applications such as in bioinformatics, multimedia, computer vision and signal processing, internet search and information retrieval, datamining and textmining, finance, fraud detection, measurement systems and process control, and several others. Currently, the development of new technologies enables to generate massive amounts of data containing a wealth of information that remains to become explored. Often the dimensionality of the input spaces in these novel applications is huge. In the analysis of microarray data, for example, where expression levels of thousands of genes need to be analyzed given only a limited number of experiments. Without performing dimensionality reduction, the classical statistical paradigms show fundamental shortcomings at this point. Facing these new challenges, there is a need for new mathematical foundations and models such that the data can become processed in a reliable way. These subjects are very interdisciplinary and relate to problems studied in neural networks, machine learning, mathematics and statistics.



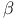 -mixing
-mixing 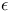 -insensitive loss function
-insensitive loss function 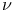 -support vector classifiers
-support vector classifiers  |
|
О проекте
|
|
О проекте