|
|
 |
| Авторизация |
|
|
|
| Поиск по указателям |
|
|
|
|
|
|
|
 |
|
|
|
| BertsekasD., Tsitsiklis J. — Neuro-Dynamic Programming (Optimization and Neural Computation Series, 3) |
|
|
|
| Предметный указатель |
Action network 262 273 316 374 380
Actor 36 224
Advantages 339 382
Aggregation of states 68 341 382
Approximation in policy space 9 261
Architectures 5 60
Architectures, linear 61
Architectures, local-global 71 88
Architectures, nonlinear 62
Architectures, power 257
Average cost problems 15 386
Backgammon 8 452
Backpropagation 65 374 375
Basis functions 61
Batch gradient method 108
batching 113
Bellman error methods 364 408
Bellman's equation 2 16 22 40 389 411
Bellman's equation, reduced 49 51 52 368
Boundedness in stochastic approximation 159 178
Cellular systems 53
Chain rule 465
Channel allocation 53 448
Chattering 320 369
Checkers 380
Chess 4
Combinatorial optimization 54 56 58 74 440 456
Compact representations 4 180
Condition number 100 115
Consistent estimator 182
Continuous-state problems 305 370
Continuously differentiable functions 464
Contraction 154
Contraction, weighted Euclidean norm 353
Contraction, weighted maximum norm 23 155
Control space complexity 268
Convergence, 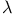 -policy iteration 45 -policy iteration 45
Convergence, approximate value iteration 344 354 364
Convergence, asynchronous policy iteration 33
Convergence, asynchronous value iteration 27 240
Convergence, constant stepsize gradient methods 94
Convergence, diminishing stepsize gradient methods 96
Convergence, extended Kalman filter 125
Convergence, geometric 100
Convergence, gradient methods with errors 121
Convergence, incremental gradient methods 115 123 143 145
Convergence, issues 93
Convergence, linear 100
Convergence, martingale 149
Convergence, off-line TD methods 208
Convergence, on-line TD methods 219
Convergence, policy iteration 30 41
Convergence, Q-learning 247 337 361 402
Convergence, rate of heavy ball method 105
Convergence, rate of steepest descent 99
Convergence, simulation-based value iteration 240
Convergence, stochastic approximation 154
Convergence, stochastic gradient methods 142
Convergence, stochastic pseudogradient methods 141 148
Convergence, sublinear 100
Convergence, supermartingale 148
Convergence, synchronous optimistic TD(1) 232
Convergence, TD methods for discounted problems 222
Convergence, TD() 199
Convergence, TD() with linear architectures 294 308
Convergence, TD-based policy iteration 45
Convex sets and functions 80 465
Cost-to-go 2 13
Cost-to-go, approximate 3 256
Cost-to-go, reduced 49 51
Critic 36 224 262 380
Data block 81 108
Decomposition of linear least squares problems 87
Decomposition, state space 28 71 331
Descent direction 89 140
Differential cost 390
discount factor 12
Discounted problems 15 37
Discounted problems, conversion to stochastic shortest paths 39
Discounted problems, error bounds 262 275
Discounted problems, optimistic TD() 313
Discounted problems, Q-learning 250
Discounted problems, TD methods 204 222 290 294
Discrete optimization 54 56 74
Dual heuristic DP 380
Dynamic programming operator 19 37
Eigenvalues 461
Elevator dispatching 456
Eligibility coefficients 202 209 295
Error bounds, approximate policy iteration 275 381
Error bounds, approximate value iteration 332 349 357
Error bounds, Bellman error methods 369
Error bounds, greedy policies 262
Error bounds, optimistic policy iteration 318 328
Error bounds, Q-learning 361
Error bounds, TD() 302 312
Every-visit method 187 189 194 197 202 251
Exploration 238 251 317
Exponential forgetting 85
Extended NDP solution 444
Fading factor 85 126
features 6 66
Features and aggregation 68
Features and heuristic policies 72 441
Features, feature iteration 67 380 427
Finite horizon problems 12 13 17 329
First passage time 47 473
First-visit method 189 194 197 202 251
Fixed point 134
Football 426
Games 408 453
Gauss — Newton method 90 124 126 130
Global minimum 78
Gradient 464
Gradient matrix 465
Gradient methods 89
Gradient methods with errors 105 121 142
Gradient methods, initialization 115
Hamilton — Jacobi equation 371
Heavy ball method 104
Heuristic DP 380
Heuristic policies 72 433
Hidden layer 62
Ill-conditioning 100 103
Imperfect state information 69
Incremental gradient methods 108 130 143 145 178 275 335 365 367 372
Incremental gradient methods with constant stepsize 113
Incremental gradient methods, convergence 115 123 143 145
Infinite horizon problems 12 14
Initialization 115
Invariant distribution 473
Iterative resampling 193
Jacobian 465
Job-shop scheduling 456
Kalman filter 83 128 252 275 316 430
Kalman filter, extended 124 130
Least squares 77
Levenberg — Marquardt method 91
Limit cycling 112
Limit inferior 463
Limit point 463
Limit superior 463
Linear least squares 81 128
Linear least squares, incremental gradient methods 117
Linear programming 36 375 383 398
Linearly (in)dependent vectors 459
Lipschitz continuity 95
Local minimum 78
| Local search 56
Logistic function 62
Lookup table representations 4 180
Lyapunov function 139
Maintenance problem 51 58 268 440
Markov noise 173
Martingales 149
Maximum norm 39
Mean value theorem 464
Momentum term 104 111
Monotone mappings 158
Monotonicity Lemma 21 38
Monte Carlo simulation 181
Monte Carlo simulation and policy iteration 270
Monte Carlo simulation and temporal differences 193
Multilayer perceptrons 62 129 429 454
Multilayer perceptrons, approximation capability 66
Multistage lookahead 30 41 264 266
Neural networks 6 62 76 103 129
Newton's method 89 91 101
Norm 459
Norm, Euclidean 459
Norm, maximum 39 459
Norm, weighted maximum 23 155 460
Norm, weighted quadratic 296
ODE approach 171 178 183 402
Optimal stopping 358
Optimality conditions 78
Parameter estimation 77
Parking 422
Partition, greedy 227 322
Partitioning 70 427
Policy 2 12
Policy evaluation 29 186
Policy evaluation, approximate 271 284 366 371
Policy improvement 29 192
Policy iteration 29 41
Policy iteration, -policy iteration 42 58 315 437
Policy iteration, approximate 269
Policy iteration, asynchronous 32 41 58
Policy iteration, average cost problems 397 405
Policy iteration, convergence 30
Policy iteration, games 412 414
Policy iteration, modified 32 41 58
Policy iteration, multistage lookahead 30
Policy iteration, optimistic 224 252 312 427 430 437 448 454
Policy iteration, partially optimistic 231 317
Policy iteration, Q-learning 338
Policy iteration, simulation-based 192
Policy iteration, temporal difference-based 41 437
Policy, greedy 226 238 259
Policy, improper 18
Policy, proper 18
Policy, stationary 13
Position evaluators 4 453
Positive definite matrices 462
Potential function 139
Projection 304
Projection in stochastic approximation 160
Pseudo-contraction, Euclidean norm 146
Pseudo-contraction, weighted maximum norm 155
Pseudogradient 140 178
Q-factors 4 192 245 256 260 261 271 367
Q-learning 180 245 253 337 352 358 380 399 415
Quadratic minimization 80 99
Quasi-Newton methods 90
Rank 460
Real-time dynamic programming 253
Recurrent class 472
Regular NDP solution 444
Reinforcement learning 8 10
Robbins — Monro 133 195 196
Rollout policy 266 455
Sarsa 339
Scaling, diagonal 101
Scaling, input 114
Selective lookahead 265
Semidefinite matrices 462
Sequential games 412 453
Sigmoidal function 62
Singular value decomposition 82 128 430 447
Soft partitioning 72
Stationary point 79
Steady-state distribution 473
Steepest descent method 89 99
Steepest descent method with momentum 104 111
Steepest descent method, diagonally scaled 101
stepsize 92
Stepsize, diminishing 92 111 129
Stepsize, incremental gradient methods 111 120
Stepsize, randomness 137
Stepsize, stochastic approximation 135
Stepsize, TD methods 218
Stochastic approximation 133
Stochastic gradient method 142 365
Stochastic matrix 471
Stochastic programming 441
Stochastic shortest paths 15 17
Stopping time 202
Strict minimum 78
Strong Law of Large Numbers 182
Sufficient statistics 69
Super martingale convergence 148
Supervised learning 453
TD() 195 429 438 454
TD(), approximate policy evaluation 284
TD(), choice of 200
TD(), convergence 199
TD(), discounted problems 204 290 294
TD(), divergence 291
TD(), every-visit 197 202
TD(), first-visit 197 202
TD(), games 417
TD(), least squares 252
TD(), off-line 198 208 286
TD(), on-line 198 204 219 224 252 286
TD(), optimistic 225 313 314 454
TD(), replace 252
TD(), restart 202 252
TD(), stepsize selection 218
TD(), synchronous 232
TD(0) 196 229 231 287 306 325 336 337 351 369 448
TD(1) 196 232 284 285 289 325 327 328
Temporal differences 41 180 193 381
Temporal differences, general temporal difference methods 201
Temporal differences, least squares 252
Temporal differences, Monte Carlo simulation 193
Termination state 15 17
Tetris 50 58 435
Training 6 60 76
Transient states 472
Two-pass methods 147 178
Two-sample methods 366 368 382
Unbiased estimator 181
Value iteration 25 42
Value iteration with state aggregation 341
Value iteration, approximate 329 341 353 362
Value iteration, asynchronous 26 58 396
Value iteration, average cost problems 391
Value iteration, contracting 393 401
Value iteration, Gauss — Seidel 26 28
Value iteration, incremental 335
Value iteration, relative 392 399
Value iteration, simulation-based 237
Wald's identity 185
Weighted maximum norm 23 155
Weighted maximum norm, contractions 23
Weights, neural network 64
|
|
|
| Реклама |
|
|
|


 |
|
О проекте
|
|
О проекте